# Kafka概述
# 拓扑
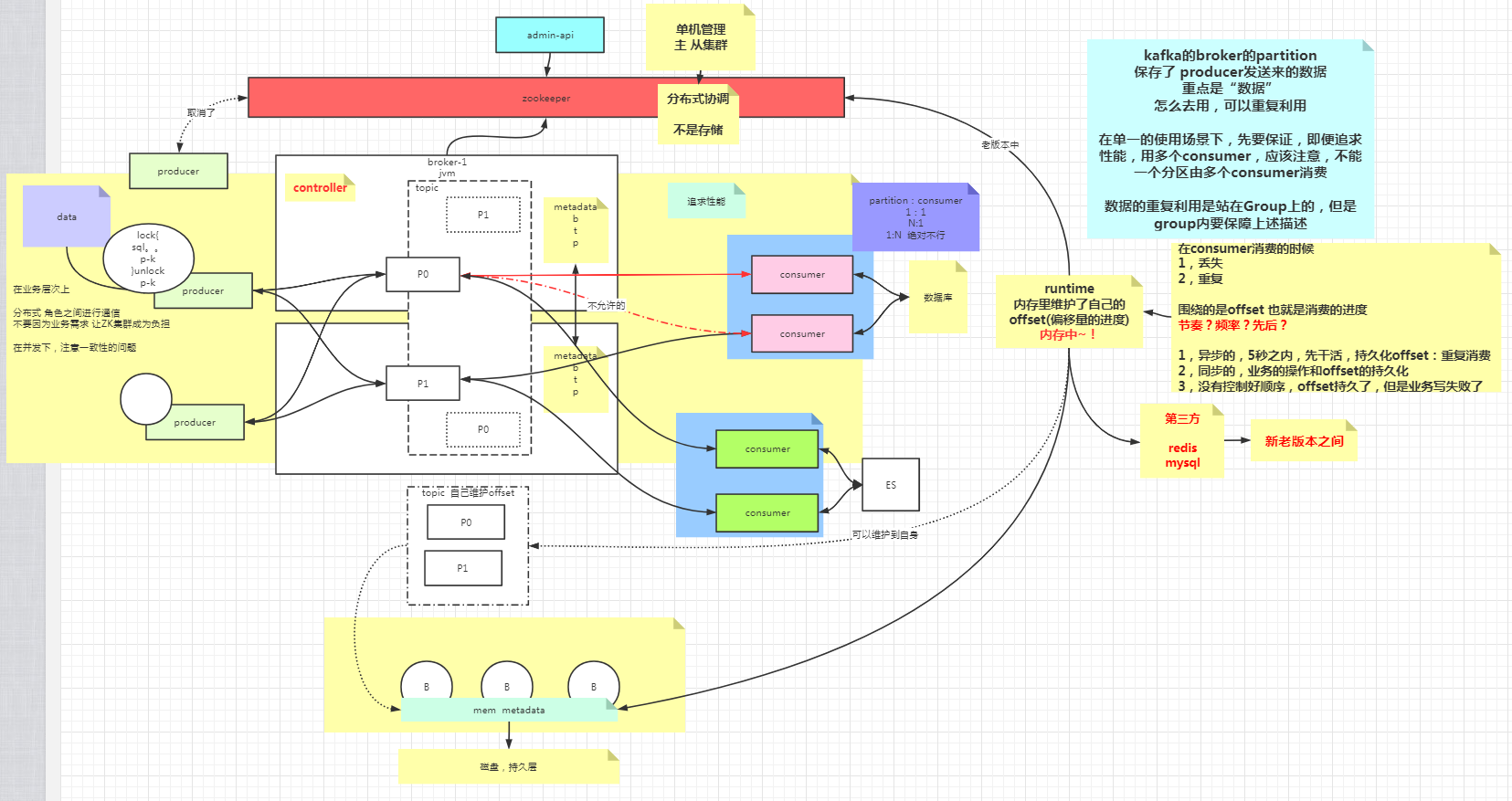
# 角色
# broker
一个服务
# topic
业务上的一个划分,topic本身是一个虚无的东西,由分区来承载
# partition
分区
老版本从zk获取可用的分区地址,新版本直接从broker获取
ReplicationFactor分区副本
分区增加副本并不能提高性能,只是增加可靠性
# controller
# producer
# consumer
partition和consumer的配比
1:1
n:1
1:n 不可行
不允许一个分区由多个消费者来消费,目的是保证顺序性,但是可以通过offset来控制
分组
- 可以是多个消费者组成一个消费者组
- 多个组消费时可以同时获取到生产者发来的数据
可能出现的问题
- 数据丢失
- 重复消费
# 集群搭建
# 准备
node01-node04
Kafka:node01-node03
zookeeper:node02-node04
# 配置启动zookeper
参见zookeeper章节
# 配置启动Kafka
安装
tar -zxvf kafka_2.12-2.7.0.tgz
mv kafka_2.12-2.7.0 /opt/
配置环境变量
vi /etc/profile1配置文件
vi $KAFKA_HOME/config/server.properties1broker.id=0 listener=PLAINTEXT://node01:9092 log.dirs=/var/kafka zookeeper.connect=node01:2181,node02:2181,node03:2181/kafka1
2
3
4同步配置到其他节点
scp
启动
kafak-server-start.sh ./server.properties
# 其他操作
topic
kafka-topics.sh --zookeeper node02:2181,node03:2181/kafka --create --topic ooxx --partitions 2 --replication-factor 2 #创建topic #--zookeeper 通过zookeeper找到controller #--topic 主题 #--partitions 分区数 #--replication-factor 分区副本因子 kafka-topics.sh --zookeeper node02:2181,node03:2181/kafka --list kafka-topics.sh --zookeeper node02:2181,node03:2181/kafka --describe --topic ooxx1
2
3
4
5
6
7
8Error while executing topic command : Replication factor: 2 larger than available brokers: 0配置文件中zookeeper.connect后面没有加“/kafka",命令中这个路径需要跟配置文件中的路径统一
consumer
kafka-console-consumer.sh --bootstrap-server node01:9092,node02:9092 --topic ooxx kafka-console-consumer.sh --bootstrap-server node01:9092,node02:9092 --topic ooxx --group msb #--group 消费者组 kafka-consumer-groups.sh --bootstrap-server node01:9092,node02:9092 --list kafka-consumer-groups.sh --bootstrap-server node01:9092,node02:9092 --describe --group msb1
2
3
4
5producer
kafka-console-producer.sh --broker-list node03:9092 --topic ooxx1
# Kafka前瞻
# 顺序处理
producer
consumer
分析要点
- 推送&拉取
- 拉取粒度
- 更新offset粒度
推送
server主动推送
会造成网卡打满
拉取
拉取,consumer自主按需去订阅拉取server的数据
拉取的粒度
单条
批次
单线程处理
一条一条处理,处理完更新offset
单线程,按顺序,单条处理,offset就是递增的,无论对db,offset频率,成本有点高,CPU,网卡,资源浪费
进度控制,精度
多线程处理
使用多线程是追求性能,减少事务,减少对数据库的性能压榨
每种类型的数据由同一个线程处理,保证顺序性
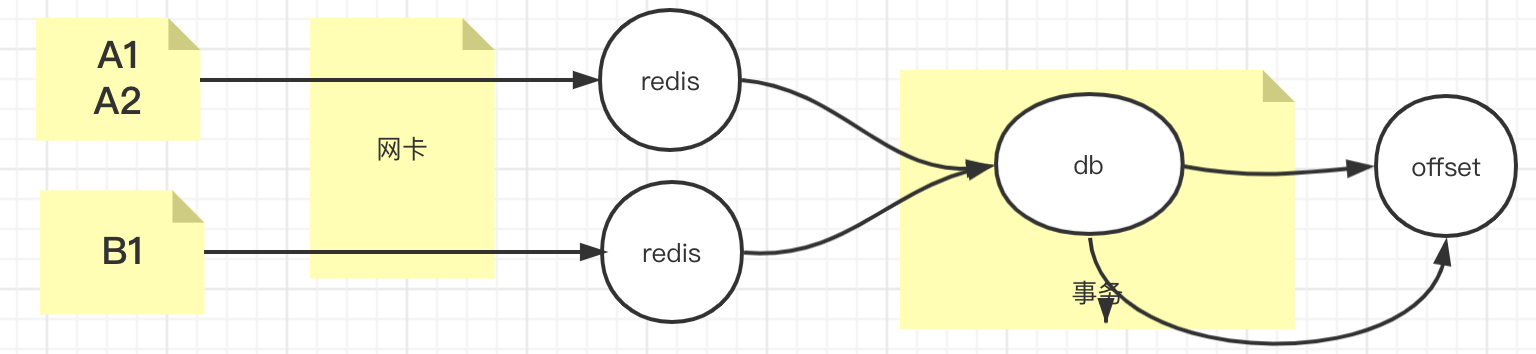
- 如果批次中有数据处理失败了(中间成功两边失败,两边成功中间失败),其他都成功了,如何更新offset?按批?还是按条?
- 会造成丢数据、重复消费
- 如果批次中有数据处理失败了(中间成功两边失败,两边成功中间失败),其他都成功了,如何更新offset?按批?还是按条?
流式计算
流式的多线程,能多线程的多线程,但是,将整个批次的事务环节交给一个线程,做到这个批次,要么成功,要么失败,减少对DB的压力,和offset频率压力,更多的去利用CPU,网卡硬件资源
粒度比较粗了
# API
环境准备
启动zookeeper
zkServer.sh start1启动kafka
kafka-server-start.sh ./server.properties1创建topic
kafka-topics.sh --zookeeper localhost:2181/kafka --create --topic ooxx --partitions 1 --replication-factor 11
添加依赖
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.1.0</version> </dependency>1
2
3
4
5生产者
@Test public void producer() throws ExecutionException, InterruptedException { String topic = "ooxx"; Properties p = new Properties(); p.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"node02:9092,node03:9092,node01:9092"); //kafka 持久化数据的MQ 数据-> byte[],不会对数据进行干预,双方要约定编解码 //kafka是一个app::使用零拷贝 sendfile 系统调用实现快速数据消费 p.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); p.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName()); p.setProperty(ProducerConfig.ACKS_CONFIG, "-1"); KafkaProducer<String, String> producer = new KafkaProducer<String, String>(p); //现在的producer就是一个提供者,面向的其实是broker,虽然在使用的时候我们期望把数据打入topic /* msb-items 2partition 三种商品,每种商品有线性的3个ID 相同的商品最好去到一个分区里 */ while(true){ for (int i = 0; i < 3; i++) { for (int j = 0; j <3; j++) { ProducerRecord<String, String> record = new ProducerRecord<>(topic, "item"+j,"val" + i); Future<RecordMetadata> send = producer .send(record); RecordMetadata rm = send.get(); int partition = rm.partition(); long offset = rm.offset(); System.out.println("key: "+ record.key()+" val: "+record.value()+" partition: "+partition + " offset: "+offset); } } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39消费者
@Test public void consumer(){ /* kafka-consumer-groups.sh --bootstrap-server node02:9092 --list */ //基础配置 Properties p = new Properties(); p.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"node02:9092,node03:9092,node01:9092"); p.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); p.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName()); //消费的细节 p.setProperty(ConsumerConfig.GROUP_ID_CONFIG,"OOXX"); //KAKFA IS MQ IS STORAGE p.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");//第一次启动,米有offset /** * "What to do when there is no initial offset in Kafka or if the current offset * does not exist any more on the server * (e.g. because that data has been deleted): * <ul> * <li>earliest: automatically reset the offset to the earliest offset * <li>latest: automatically reset the offset to the latest offset</li> * <li>none: throw exception to the consumer if no previous offset is found for the consumer's group</li><li>anything else: throw exception to the consumer.</li> * </ul>"; */ p.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true");//自动提交时异步提交,丢数据&&重复数据 //一个运行的consumer ,那么自己会维护自己消费进度 //一旦你自动提交,但是是异步的 //1,还没到时间,挂了,没提交,重起一个consuemr,参照offset的时候,会重复消费 //2,一个批次的数据还没写数据库成功,但是这个批次的offset背异步提交了,挂了,重起一个consuemr,参照offset的时候,会丢失消费 // p.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"15000");//5秒 // p.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,""); // POLL 拉取数据,弹性,按需,拉取多少? KafkaConsumer<String, String> consumer = new KafkaConsumer<>(p); //kafka 的consumer会动态负载均衡 consumer.subscribe(Arrays.asList("ooxx"), new ConsumerRebalanceListener() { @Override public void onPartitionsRevoked(Collection<TopicPartition> partitions) { System.out.println("---onPartitionsRevoked:"); Iterator<TopicPartition> iter = partitions.iterator(); while(iter.hasNext()){ System.out.println(iter.next().partition()); } } @Override public void onPartitionsAssigned(Collection<TopicPartition> partitions) { System.out.println("---onPartitionsAssigned:"); Iterator<TopicPartition> iter = partitions.iterator(); while(iter.hasNext()){ System.out.println(iter.next().partition()); } } }); /** * 以下代码是你再未来开发的时候,向通过自定时间点的方式,自定义消费数据位置 * * 其实本质,核心知识是seek方法 * * 举一反三: * 1,通过时间换算出offset,再通过seek来自定义偏移 * 2,如果你自己维护offset持久化~!!!通过seek完成 * */ Map<TopicPartition, Long> tts =new HashMap<>(); //通过consumer取回自己分配的分区 as Set<TopicPartition> as = consumer.assignment(); while(as.size()==0){ consumer.poll(Duration.ofMillis(100)); as = consumer.assignment(); } //自己填充一个hashmap,为每个分区设置对应的时间戳 for (TopicPartition partition : as) { // tts.put(partition,System.currentTimeMillis()-1*1000); tts.put(partition,1610629127300L); } //通过consumer的api,取回timeindex的数据 Map<TopicPartition, OffsetAndTimestamp> offtime = consumer.offsetsForTimes(tts); for (TopicPartition partition : as) { //通过取回的offset数据,通过consumer的seek方法,修正自己的消费偏移 OffsetAndTimestamp offsetAndTimestamp = offtime.get(partition); long offset = offsetAndTimestamp.offset(); //不是通过time 换 offset,如果是从mysql读取回来,其本质是一样的 System.out.println(offset); consumer.seek(partition,offset); } try { System.in.read(); } catch (IOException e) { e.printStackTrace(); } while(true){ /** * 常识:如果想多线程处理多分区 * 每poll一次,用一个语义:一个job启动 * 一次job用多线程并行处理分区 * 且,job应该被控制是串行的 * 以上的知识点,其实如果你学过大数据 */ //微批的感觉 ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(0));// 0~n if(!records.isEmpty()){ //以下代码的优化很重要 System.out.println("----count-------"+records.count()+"-------------"); Set<TopicPartition> partitions = records.partitions(); //每次poll的时候是取多个分区的数据 //且每个分区内的数据是有序的 /** * 如果手动提交offset * 1,按消息进度同步提交 * 2,按分区粒度同步提交 * 3,按当前poll的批次同步提交 * * 思考:如果在多个线程下 * 1,以上1,3的方式不用多线程 * 2,以上2的方式最容易想到多线程方式处理,有没有问题? */ for (TopicPartition partition : partitions) { List<ConsumerRecord<String, String>> pRecords = records.records(partition); // pRecords.stream().sorted() //在一个微批里,按分区获取poll回来的数据 //线性按分区处理,还可以并行按分区处理用多线程的方式 Iterator<ConsumerRecord<String, String>> piter = pRecords.iterator(); while(piter.hasNext()){ ConsumerRecord<String, String> next = piter.next(); int par = next.partition(); long offset = next.offset(); String key = next.key(); String value = next.value(); long timestamp = next.timestamp(); System.out.println("key: "+ key+" val: "+ value+ " partition: "+par + " offset: "+ offset+"time:: "+ timestamp); TopicPartition sp = new TopicPartition("msb-items", par); OffsetAndMetadata om = new OffsetAndMetadata(offset); HashMap<TopicPartition, OffsetAndMetadata> map = new HashMap<>(); map.put(sp,om); consumer.commitSync(map);//这个是最安全的,每条记录级的更新,第一点 //单线程,多线程,都可以 } long poff = pRecords.get(pRecords.size() - 1).offset();//获取分区内最后一条消息的offset OffsetAndMetadata pom = new OffsetAndMetadata(poff); HashMap<TopicPartition, OffsetAndMetadata> map = new HashMap<>(); map.put(partition,pom); consumer.commitSync( map );//这个是第二种,分区粒度提交offset /** * 因为你都分区了 * 拿到了分区的数据集 * 期望的是先对数据整体加工 * 小问题会出现? 你怎么知道最后一条小的offset?!!!! * 感觉一定要有,kafka,很傻,你拿走了多少,我不关心,你告诉我你正确的最后一个小的offset */ } consumer.commitSync();//这个就是按poll的批次提交offset,第3点 // Iterator<ConsumerRecord<String, String>> iter = records.iterator(); // while(iter.hasNext()){ // //因为一个consuemr可以消费多个分区,但是一个分区只能给一个组里的一个consuemr消费 // ConsumerRecord<String, String> record = iter.next(); // int partition = record.partition(); // long offset = record.offset(); // String key = record.key(); // String value = record.value(); // // System.out.println("key: "+ record.key()+" val: "+ record.value()+ " partition: "+partition + " offset: "+ offset); // } } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200