# 基本概念
# 什么是线程
# 进程、线程、纤程/协程的区别
进程
操作系统分配资源的基本单元
线程
程序中不同的执行路径
CPU调度的基本单元
线程/协程
用户空间内的线程
为什么产生
让线程之间的切换更简单——放到用户空间
和线程的区别
- 一个比较重,一个较轻
- 一个在用户空间,一个在内核空间
- 一个支持启动的数量比较大,一个比较小
# 线程的启动方式
Thread
Runnable
lambda
Executors.newCachedThread
Callable
类似于Runnable,相比Runnable,run方法多个返回值
Future
存储执行的将来才会产生的结果
获取结果通过get()方法, 是阻塞的
FutureTask
既是任务,也可以存储结果 Future+Runnable
CompletableFuture
用来管理多个Future结果
# 线程的状态
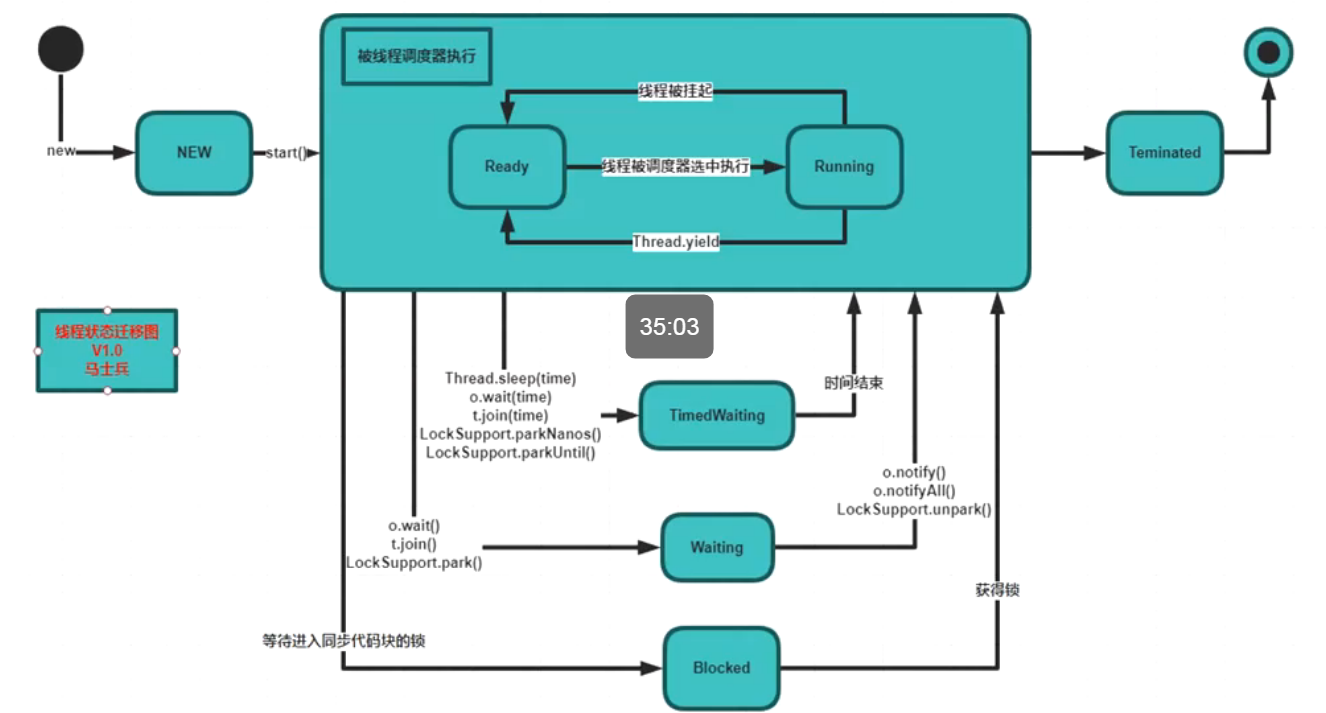
# 线程的常用API
sleep
睡眠一段时间,
yield
让出一下cpu,自己重新进入等待队列中runnable状态
join
一个线程执行中调用执行另外一个线程,等另外一个线程执行完之后再继续执行当前线程
interrupt
异常处理逻辑
stop
太暴力,不建议使用
会抛出java.lang.ThreadDeath Error
如果暴力让线程停止可能会使一些清理性的工作得不到完成。其次,可能会造成数据不一致的问题
wait
锁对象调用该方法使当前线程进入等待状态,并立刻释放锁对象,直到被其他线程唤醒进入等锁池
notify
随机唤醒一个处于等待中的线程(同一个等待阻塞池中)
不释放锁
notifyAll
唤醒所有等待中的线程(同一个等待阻塞池中)
suspend & resume
# Synchronized
# 用法
synchronized(Object)
- 锁的是对象不是代码
- 对象头上面的前两位来标识是否加了锁
- 这个object不能用string常量、Integer、Long以及基础数据类型
this、XX.class
加锁的方法和没有加锁的方法可以同时执行
可能会产生脏读,比如说银行存钱+查看余额
可重入锁 同一个类里面的两个synchronized s1 and s2,是允许s1调用s2的,也就是同个线程如果要申请同一个锁是可以被允许的 如果不可重入子类继承父类的synchroized的方法就会出问题了
异常跟锁 如果程序抛出异常,默认锁会释放
# 用户态与内核态
硬件支持:CPU的指令级别 ring0-ring3
JDK早期,synchronized 叫做重量级锁, 因为申请锁资源必须通过kernel, 系统调用
;hello.asm
;write(int fd, const void *buffer, size_t nbytes)
section data
msg db "Hello", 0xA
len equ $ - msg
section .text
global _start
_start:
mov edx, len
mov ecx, msg
mov ebx, 1 ;文件描述符1 std_out
mov eax, 4 ;write函数系统调用号 4
int 0x80
mov ebx, 0
mov eax, 1 ;exit函数系统调用号
int 0x80
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# CAS
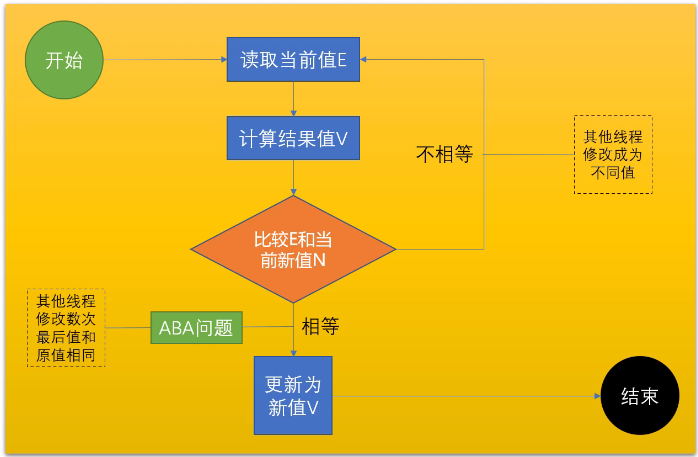
Compare And Swap (Compare And Exchange) / 自旋 / 自旋锁 / 无锁 (无重量锁)
因为经常配合循环操作,直到完成为止,所以泛指一类操作
cas(v, a, b) ,变量v,期待值a, 修改值b,cas是CPU的原语支持
自旋就是你空转等待,一直等到她接纳你为止
ABA问题,你的女朋友在离开你的这段儿时间经历了别的人
解决办法(版本号 AtomicStampedReference),基础类型简单值不需要版本号
# Unsafe
AtomicInteger:
public final int incrementAndGet() {
for (;;) {
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return next;
}
}
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
2
3
4
5
6
7
8
9
10
11
12
Unsafe:
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
运用:
package com.mashibing.jol;
import sun.misc.Unsafe;
import java.lang.reflect.Field;
public class T02_TestUnsafe {
int i = 0;
private static T02_TestUnsafe t = new T02_TestUnsafe();
public static void main(String[] args) throws Exception {
//Unsafe unsafe = Unsafe.getUnsafe();
Field unsafeField = Unsafe.class.getDeclaredFields()[0];
unsafeField.setAccessible(true);
Unsafe unsafe = (Unsafe) unsafeField.get(null);
Field f = T02_TestUnsafe.class.getDeclaredField("i");
long offset = unsafe.objectFieldOffset(f);
System.out.println(offset);
boolean success = unsafe.compareAndSwapInt(t, offset, 0, 1);
System.out.println(success);
System.out.println(t.i);
//unsafe.compareAndSwapInt()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
jdk8u: unsafe.cpp:
cmpxchg = compare and exchange
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_END
2
3
4
5
6
jdk8u: atomic_linux_x86.inline.hpp 93行
is_MP = Multi Processor
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest, jint compare_value) {
int mp = os::is_MP();
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
2
3
4
5
6
7
8
jdk8u: os.hpp is_MP()
static inline bool is_MP() {
// During bootstrap if _processor_count is not yet initialized
// we claim to be MP as that is safest. If any platform has a
// stub generator that might be triggered in this phase and for
// which being declared MP when in fact not, is a problem - then
// the bootstrap routine for the stub generator needs to check
// the processor count directly and leave the bootstrap routine
// in place until called after initialization has ocurred.
return (_processor_count != 1) || AssumeMP;
}
2
3
4
5
6
7
8
9
10
jdk8u: atomic_linux_x86.inline.hpp
#define LOCK_IF_MP(mp) "cmp $0, " #mp "; je 1f; lock; 1: "
最终实现:
cmpxchg = cas修改变量值
lock cmpxchg 指令
硬件:
lock指令在执行后面指令的时候锁定一个北桥信号
(不采用锁总线的方式)
# markword
对象的内存布局
8字节markword + 4字节的类型指正class pointer + 成员变量xxx
8字节对齐
markword中记录了锁、gc等信息
# 工具:JOL = Java Object Layout
<dependencies>
<!-- https://mvnrepository.com/artifact/org.openjdk.jol/jol-core -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
</dependencies>
2
3
4
5
6
7
8
public class HelloJol {
public static void main(String[] args) {
Object o = new Object();
System.out.println(ClassLayout.parseInstance(o).toPrintable());
synchronized (o){
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}
}
2
3
4
5
6
7
8
9
0 new #2 <java/lang/Object>
3 dup
4 invokespecial #1 <java/lang/Object.<init>>
7 astore_1
8 getstatic #3 <java/lang/System.out>
11 aload_1
12 invokestatic #4 <org/openjdk/jol/info/ClassLayout.parseInstance>
15 invokevirtual #5 <org/openjdk/jol/info/ClassLayout.toPrintable>
18 invokevirtual #6 <java/io/PrintStream.println>
21 aload_1
22 dup
23 astore_2
24 monitorenter
25 getstatic #3 <java/lang/System.out>
28 aload_1
29 invokestatic #4 <org/openjdk/jol/info/ClassLayout.parseInstance>
32 invokevirtual #5 <org/openjdk/jol/info/ClassLayout.toPrintable>
35 invokevirtual #6 <java/io/PrintStream.println>
38 aload_2
39 monitorexit
40 goto 48 (+8)
43 astore_3
44 aload_2
45 monitorexit
46 aload_3
47 athrow
48 return
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
jdk8u: markOop.hpp
// Bit-format of an object header (most significant first, big endian layout below):
//
// 32 bits:
// --------
// hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
// size:32 ------------------------------------------>| (CMS free block)
// PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)
//
// 64 bits:
// --------
// unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
// PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
// size:64 ----------------------------------------------------->| (CMS free block)
//
// unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)
// JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)
// narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)
// unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# synchronized的横切面详解
- synchronized原理
- 升级过程
- 汇编实现
- vs reentrantLock的区别
# java源码层级
synchronized(o)
# 字节码层级
monitorenter moniterexit
# JVM层级(Hotspot)
package com.mashibing.insidesync;
import org.openjdk.jol.info.ClassLayout;
public class T01_Sync1 {
public static void main(String[] args) {
Object o = new Object();
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}
2
3
4
5
6
7
8
9
10
11
12
com.mashibing.insidesync.T01_Sync1$Lock object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 00 00 00 (00000101 00000000 00000000 00000000) (5)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 49 ce 00 20 (01001001 11001110 00000000 00100000) (536923721)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
2
3
4
5
6
7
8
com.mashibing.insidesync.T02_Sync2$Lock object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 05 90 2e 1e (00000101 10010000 00101110 00011110) (506368005)
4 4 (object header) 1b 02 00 00 (00011011 00000010 00000000 00000000) (539)
8 4 (object header) 49 ce 00 20 (01001001 11001110 00000000 00100000) (536923721)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes tota
2
3
4
5
6
7
8
InterpreterRuntime:: monitorenter方法
IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorenter(JavaThread* thread, BasicObjectLock* elem))
#ifdef ASSERT
thread->last_frame().interpreter_frame_verify_monitor(elem);
#endif
if (PrintBiasedLockingStatistics) {
Atomic::inc(BiasedLocking::slow_path_entry_count_addr());
}
Handle h_obj(thread, elem->obj());
assert(Universe::heap()->is_in_reserved_or_null(h_obj()),
"must be NULL or an object");
if (UseBiasedLocking) {
// Retry fast entry if bias is revoked to avoid unnecessary inflation
ObjectSynchronizer::fast_enter(h_obj, elem->lock(), true, CHECK);
} else {
ObjectSynchronizer::slow_enter(h_obj, elem->lock(), CHECK);
}
assert(Universe::heap()->is_in_reserved_or_null(elem->obj()),
"must be NULL or an object");
#ifdef ASSERT
thread->last_frame().interpreter_frame_verify_monitor(elem);
#endif
IRT_END
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
synchronizer.cpp
revoke_and_rebias
void ObjectSynchronizer::fast_enter(Handle obj, BasicLock* lock, bool attempt_rebias, TRAPS) {
if (UseBiasedLocking) {
if (!SafepointSynchronize::is_at_safepoint()) {
BiasedLocking::Condition cond = BiasedLocking::revoke_and_rebias(obj, attempt_rebias, THREAD);
if (cond == BiasedLocking::BIAS_REVOKED_AND_REBIASED) {
return;
}
} else {
assert(!attempt_rebias, "can not rebias toward VM thread");
BiasedLocking::revoke_at_safepoint(obj);
}
assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now");
}
slow_enter (obj, lock, THREAD) ;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
void ObjectSynchronizer::slow_enter(Handle obj, BasicLock* lock, TRAPS) {
markOop mark = obj->mark();
assert(!mark->has_bias_pattern(), "should not see bias pattern here");
if (mark->is_neutral()) {
// Anticipate successful CAS -- the ST of the displaced mark must
// be visible <= the ST performed by the CAS.
lock->set_displaced_header(mark);
if (mark == (markOop) Atomic::cmpxchg_ptr(lock, obj()->mark_addr(), mark)) {
TEVENT (slow_enter: release stacklock) ;
return ;
}
// Fall through to inflate() ...
} else
if (mark->has_locker() && THREAD->is_lock_owned((address)mark->locker())) {
assert(lock != mark->locker(), "must not re-lock the same lock");
assert(lock != (BasicLock*)obj->mark(), "don't relock with same BasicLock");
lock->set_displaced_header(NULL);
return;
}
#if 0
// The following optimization isn't particularly useful.
if (mark->has_monitor() && mark->monitor()->is_entered(THREAD)) {
lock->set_displaced_header (NULL) ;
return ;
}
#endif
// The object header will never be displaced to this lock,
// so it does not matter what the value is, except that it
// must be non-zero to avoid looking like a re-entrant lock,
// and must not look locked either.
lock->set_displaced_header(markOopDesc::unused_mark());
ObjectSynchronizer::inflate(THREAD, obj())->enter(THREAD);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
inflate方法:膨胀为重量级锁
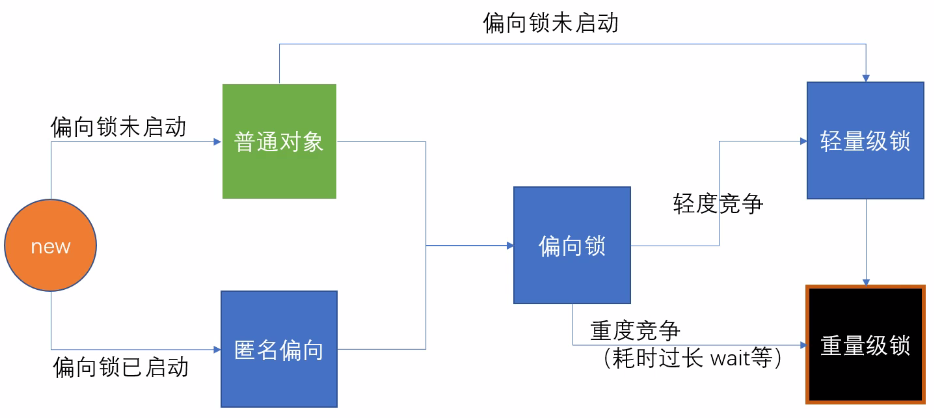
# 锁升级过程
JDK早期的 重量级 - OS(找操作系统申请锁)
由于HotSpot的作者经过研究发现,大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低从而引入偏向锁。偏向锁在获取资源的时候会在锁对象头上记录当前线程ID,偏向锁并不会主动释放,这样每次偏向锁进入的时候都会判断锁对象头中线程ID是否为自己,如果是当前线程重入,直接进入同步操作,不需要额外的操作。默认在开启偏向锁和轻量锁的情况下,当线程进来时,首先会加上偏向锁,其实这里只是用一个状态来控制,会记录加锁的线程,如果是线程重入,则不会进行锁升级。
new - 偏向锁 - 轻量级锁 (无锁, 自旋锁,自适应自旋)- 重量级锁
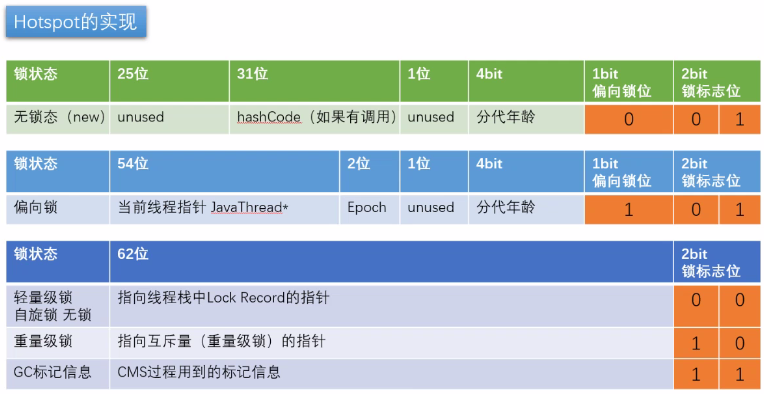
- JDK8 markword实现表:
new ->偏向锁
只有一个线程调用,直接将当前线程的id写入到markwork中,偏向锁位修改为1,标识加了偏向锁
获取偏向锁流程:
- 判断是否为可偏向状态--MarkWord中锁标志是否为‘01’,是否偏向锁是否为‘1’
- 如果是可偏向状态,则查看线程ID是否为当前线程,如果是,则进入步骤 'V',否则进入 步骤‘III’
- 通过CAS操作竞争锁,如果竞争成功,则将MarkWord中线程ID设置为当前线程ID,然 后执行‘V’;竞争失败,则执行‘IV’
- CAS获取偏向锁失败表示有竞争。当达到safepoint时获得偏向锁的线程被挂起,偏向锁 升级为轻量级锁,然后被阻塞在安全点的线程继续往下执行同步代码块
- 执行同步代码
偏向锁->自旋锁
争抢锁的线程在自己的线程栈中加入LR(LockRecord),争抢将LR指针放入markword中,失败的自旋等待
轻量级锁获取过程:
- 进行加锁操作时,jvm会判断是否已经是重量级锁,如果不是,则会在当前线程栈帧中划出一块空间,作为该锁的锁记录,并且将锁对象MarkWord复制到该锁记录中
- 复制成功之后,jvm使用CAS操作将对象头MarkWord更新为指向锁记录的指针,并将锁记录里的owner指针指向对象头的MarkWord。如果成功,则执行‘III’,否则执行‘IV’
- 更新成功,则当前线程持有该对象锁,并且对象MarkWord锁标志设置为‘00’,即表示此对象处于轻量级锁状态
- 更新失败,jvm先检查对象MarkWord是否指向当前线程栈帧中的锁记录,如果是则执行‘V’,否则执行‘VI’
- 表示锁重入;然后当前线程栈帧中增加一个锁记录第一部分(Displaced Mark Word)为null,并指向Mark Word的锁对象,起到一个重入计数器的作用
- 表示该锁对象已经被其他线程抢占,则进行自旋等待(默认10次),等待次数达到阈值仍未获取到锁,则升级为重量级锁
自旋锁->重量级锁
触发条件:有线程超过10次自旋, -XX:PreBlockSpin, 或者自旋线程数超过CPU核数的一半, 1.6之后,加入自适应自旋 Adapative Self Spinning , JVM自己控制
升级重量级锁:-> 向操作系统申请资源,linux mutex , CPU从3级-0级系统调用,线程挂起,进入等待队列,等待操作系统的调度,然后再映射回用户空间
当有多个锁竞争轻量级锁则会升级为重量级锁,重量级锁正常会进入一个cxq的队列,在调用wait方法之后,则会进入一个waitSet的队列park等待,而当调用notify方法唤醒之后,则有可能进入EntryList。重量级锁加锁过程:
- 分配一个ObjectMonitor对象,把Mark Word锁标志置为‘10’,然后Mark Word存储指向ObjectMonitor对象的指针。ObjectMonitor对象有两个队列和一个指针,每个需要获取锁的线程都包装成ObjectWaiter对象
- 多个线程同时执行同一段同步代码时,ObjectWaiter先进入EntryList队列,当某个线程获取到对象的monitor以后进入Owner区域,并把monitor中的owner变量设置为当前线程同时monitor中的计数器count+1;
什么时候适合用自旋锁什么时候适合用重量级锁
执行时间短(加锁代码),线程数少,用自旋 执行时间长,线程数多,用系统锁
为什么有自旋锁还需要重量级锁?
自旋是消耗CPU资源的,如果锁的时间长,或者自旋线程多,CPU会被大量消耗
重量级锁有等待队列,所有拿不到锁的进入等待队列,不需要消耗CPU资源
偏向锁是否一定比自旋锁效率高?
不一定,在明确知道会有多线程竞争的情况下,偏向锁肯定会涉及锁撤销,这时候直接使用自旋锁
JVM启动过程,会有很多线程竞争(明确),所以默认情况启动时不打开偏向锁,过一段儿时间再打开
# synchronized优化
synchronized优化的过程和markword息息相关
用markword中最低的三位代表锁状态 其中1位是偏向锁位 两位是普通锁位
Object o = new Object() 锁 = 0 01 无锁态 注意:如果偏向锁打开,默认是匿名偏向状态
o.hashCode() 001 + hashcode
00000001 10101101 00110100 00110110 01011001 00000000 00000000 000000001
2little endian big endian
00000000 00000000 00000000 01011001 00110110 00110100 10101101 00000000
默认synchronized(o) 00 -> 轻量级锁 默认情况 偏向锁有个时延,默认是4秒 why? 因为JVM虚拟机自己有一些默认启动的线程,里面有好多sync代码,这些sync代码启动时就知道肯定会有竞争,如果使用偏向锁,就会造成偏向锁不断的进行锁撤销和锁升级的操作,效率较低。
-XX:BiasedLockingStartupDelay=01如果设定上述参数 new Object () - > 101 偏向锁 ->线程ID为0 -> Anonymous BiasedLock 打开偏向锁,new出来的对象,默认就是一个可偏向匿名对象101
如果有线程上锁 上偏向锁,指的就是,把markword的线程ID改为自己线程ID的过程 偏向锁不可重偏向 批量偏向 批量撤销
如果有线程竞争 撤销偏向锁,升级轻量级锁 线程在自己的线程栈生成LockRecord ,用CAS操作将markword设置为指向自己这个线程的LR的指针,设置成功者得到锁
如果竞争加剧 竞争加剧:有线程超过10次自旋, -XX:PreBlockSpin, 或者自旋线程数超过CPU核数的一半, 1.6之后,加入自适应自旋 Adapative Self Spinning , JVM自己控制 升级重量级锁:-> 向操作系统申请资源,linux mutex , CPU从3级-0级系统调用,线程挂起,进入等待队列,等待操作系统的调度,然后再映射回用户空间
(以上实验环境是JDK11,打开就是偏向锁,而JDK8默认对象头是无锁)
偏向锁默认是打开的,但是有一个时延,如果要观察到偏向锁,应该设定参数
如果计算过对象的hashCode,则对象无法进入偏向状态!
轻量级锁重量级锁的hashCode存在与什么地方?
答案:线程栈中,轻量级锁的LR中,或是代表重量级锁的ObjectMonitor的成员中
关于epoch: (不重要)
批量重偏向与批量撤销渊源:从偏向锁的加锁解锁过程中可看出,当只有一个线程反复进入同步块时,偏向锁带来的性能开销基本可以忽略,但是当有其他线程尝试获得锁时,就需要等到safe point时,再将偏向锁撤销为无锁状态或升级为轻量级,会消耗一定的性能,所以在多线程竞争频繁的情况下,偏向锁不仅不能提高性能,还会导致性能下降。于是,就有了批量重偏向与批量撤销的机制。
原理以class为单位,为每个class维护解决场景批量重偏向(bulk rebias)机制是为了解决:一个线程创建了大量对象并执行了初始的同步操作,后来另一个线程也来将这些对象作为锁对象进行操作,这样会导致大量的偏向锁撤销操作。批量撤销(bulk revoke)机制是为了解决:在明显多线程竞争剧烈的场景下使用偏向锁是不合适的。
一个偏向锁撤销计数器,每一次该class的对象发生偏向撤销操作时,该计数器+1,当这个值达到重偏向阈值(默认20)时,JVM就认为该class的偏向锁有问题,因此会进行批量重偏向。每个class对象会有一个对应的epoch字段,每个处于偏向锁状态对象的Mark Word中也有该字段,其初始值为创建该对象时class中的epoch的值。每次发生批量重偏向时,就将该值+1,同时遍历JVM中所有线程的栈,找到该class所有正处于加锁状态的偏向锁,将其epoch字段改为新值。下次获得锁时,发现当前对象的epoch值和class的epoch不相等,那就算当前已经偏向了其他线程,也不会执行撤销操作,而是直接通过CAS操作将其Mark Word的Thread Id 改成当前线程Id。当达到重偏向阈值后,假设该class计数器继续增长,当其达到批量撤销的阈值后(默认40),JVM就认为该class的使用场景存在多线程竞争,会标记该class为不可偏向,之后,对于该class的锁,直接走轻量级锁的逻辑。
没错,我就是厕所所长
加锁,指的是锁定对象
锁升级的过程
JDK较早的版本 OS的资源 互斥量 用户态 -> 内核态的转换 重量级 效率比较低
现代版本进行了优化
无锁 - 偏向锁 -轻量级锁(自旋锁)-重量级锁
偏向锁 - markword 上记录当前线程指针,下次同一个线程加锁的时候,不需要争用,只需要判断线程指针是否同一个,所以,偏向锁,偏向加锁的第一个线程 。hashCode备份在线程栈上 线程销毁,锁降级为无锁
有争用 - 锁升级为轻量级锁 - 每个线程有自己的LockRecord在自己的线程栈上,用CAS去争用markword的LR的指针,指针指向哪个线程的LR,哪个线程就拥有锁
自旋超过10次,升级为重量级锁 - 如果太多线程自旋 CPU消耗过大,不如升级为重量级锁,进入等待队列(不消耗CPU)-XX:PreBlockSpin
自旋锁在 JDK1.4.2 中引入,使用 -XX:+UseSpinning 来开启。JDK 6 中变为默认开启,并且引入了自适应的自旋锁(适应性自旋锁)。
自适应自旋锁意味着自旋的时间(次数)不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。
偏向锁由于有锁撤销的过程revoke,会消耗系统资源,所以,在锁争用特别激烈的时候,用偏向锁未必效率高。还不如直接使用轻量级锁。
# 锁重入
sychronized是可重入锁
重入次数必须记录,因为要解锁几次必须得对应
偏向锁 自旋锁 -> 线程栈 -> LR + 1 (每重入一次都会在线程栈中加入一个LR,LR指向了一个数据结构,其中记录了前面状态备份的displayed markword,只有第一个LR会记录,后面的都是null,包括初始化的hashcode->identity hashcode)
重量级锁 -> ? ObjectMonitor字段上
# synchronized最底层实现
public class T {
static volatile int i = 0;
public static void n() { i++; }
public static synchronized void m() {}
publics static void main(String[] args) {
for(int j=0; j<1000_000; j++) {
m();
n();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly T
C1 Compile Level 1 (一级优化)
C2 Compile Level 2 (二级优化)
找到m() n()方法的汇编码,会看到 lock comxchg .....指令
# synchronized vs Lock (CAS)
在高争用 高耗时的环境下synchronized效率更高
在低争用 低耗时的环境下CAS效率更高
synchronized到重量级之后是等待队列(不消耗CPU)
CAS(等待期间消耗CPU)
一切以实测为准
2
3
4
5
6
# 锁消除 lock eliminate
public void add(String str1,String str2){
StringBuffer sb = new StringBuffer();
sb.append(str1).append(str2);
}
2
3
4
我们都知道 StringBuffer 是线程安全的,因为它的关键方法都是被 synchronized 修饰过的,但我们看上面这段代码,我们会发现,sb 这个引用只会在 add 方法中使用,不可能被其它线程引用(因为是局部变量,栈私有),因此 sb 是不可能共享的资源,JVM 会自动消除 StringBuffer 对象内部的锁。
# 锁粗化 lock coarsening
public String test(String str){
int i = 0;
StringBuffer sb = new StringBuffer():
while(i < 100){
sb.append(str);
i++;
}
return sb.toString():
}
2
3
4
5
6
7
8
9
10
JVM 会检测到这样一连串的操作都对同一个对象加锁(while 循环内 100 次执行 append,没有锁粗化的就要进行 100 次加锁/解锁),此时 JVM 就会将加锁的范围粗化到这一连串的操作的外部(比如 while 虚幻体外),使得这一连串操作只需要加一次锁即可。
# 锁降级(不重要)
https://www.zhihu.com/question/63859501
其实,只被VMThread访问,降级也就没啥意义了。所以可以简单认为锁降级不存在!
# 超线程
一个ALU + 两组Registers + PC
# 参考资料
http://openjdk.java.net/groups/hotspot/docs/HotSpotGlossary.html
# Volatile
# 1.线程可见性
线程之间不可见
package com.mashibing.testvolatile;
public class T01_ThreadVisibility {
private static volatile boolean flag = true;
public static void main(String[] args) throws InterruptedException {
new Thread(()-> {
while (flag) {
//do sth
}
System.out.println("end");
}, "server").start();
Thread.sleep(1000);
flag = false;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
MESI
利用的CPU的缓存一致性协议
# 2.防止指令重排序
问题:DCL(double check lock)单例需不需要加volatile?
public class DCLSingleton { private static volatile DCLSingleton INSTANCE; //JIT private DCLSingleton() { } public static DCLSingleton getInstance() { if (INSTANCE == null) { //双重检查 synchronized (DCLSingleton.class) { if(INSTANCE == null) { try { Thread.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } INSTANCE = new DCLSingleton(); } } } return INSTANCE; } public void m() { System.out.println("m"); } public static void main(String[] args) { for(int i=0; i<100; i++) { new Thread(()->{ System.out.println(DCLSingleton.getInstance().hashCode()); }).start(); } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# CPU的基础知识
缓存行对齐 缓存行64个字节是CPU同步的基本单位,缓存行隔离会比伪共享效率要高 Disruptor
package com.mashibing.juc.c_028_FalseSharing; public class T02_CacheLinePadding { private static class Padding { public volatile long p1, p2, p3, p4, p5, p6, p7; // } private static class T extends Padding { public volatile long x = 0L; } public static T[] arr = new T[2]; static { arr[0] = new T(); arr[1] = new T(); } public static void main(String[] args) throws Exception { Thread t1 = new Thread(()->{ for (long i = 0; i < 1000_0000L; i++) { arr[0].x = i; } }); Thread t2 = new Thread(()->{ for (long i = 0; i < 1000_0000L; i++) { arr[1].x = i; } }); final long start = System.nanoTime(); t1.start(); t2.start(); t1.join(); t2.join(); System.out.println((System.nanoTime() - start)/100_0000); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40MESI
伪共享
伪共享的非标准定义为:缓存系统中是以缓存行(cache line)为单位存储的,当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
合并写 CPU内部的4个字节的Buffer
package com.mashibing.juc.c_029_WriteCombining; public final class WriteCombining { private static final int ITERATIONS = Integer.MAX_VALUE; private static final int ITEMS = 1 << 24; private static final int MASK = ITEMS - 1; private static final byte[] arrayA = new byte[ITEMS]; private static final byte[] arrayB = new byte[ITEMS]; private static final byte[] arrayC = new byte[ITEMS]; private static final byte[] arrayD = new byte[ITEMS]; private static final byte[] arrayE = new byte[ITEMS]; private static final byte[] arrayF = new byte[ITEMS]; public static void main(final String[] args) { for (int i = 1; i <= 3; i++) { System.out.println(i + " SingleLoop duration (ns) = " + runCaseOne()); System.out.println(i + " SplitLoop duration (ns) = " + runCaseTwo()); } } public static long runCaseOne() { long start = System.nanoTime(); int i = ITERATIONS; while (--i != 0) { int slot = i & MASK; byte b = (byte) i; arrayA[slot] = b; arrayB[slot] = b; arrayC[slot] = b; arrayD[slot] = b; arrayE[slot] = b; arrayF[slot] = b; } return System.nanoTime() - start; } public static long runCaseTwo() { long start = System.nanoTime(); int i = ITERATIONS; while (--i != 0) { int slot = i & MASK; byte b = (byte) i; arrayA[slot] = b; arrayB[slot] = b; arrayC[slot] = b; } i = ITERATIONS; while (--i != 0) { int slot = i & MASK; byte b = (byte) i; arrayD[slot] = b; arrayE[slot] = b; arrayF[slot] = b; } return System.nanoTime() - start; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62指令重排序
package com.mashibing.jvm.c3_jmm; public class T04_Disorder { private static int x = 0, y = 0; private static int a = 0, b =0; public static void main(String[] args) throws InterruptedException { int i = 0; for(;;) { i++; x = 0; y = 0; a = 0; b = 0; Thread one = new Thread(new Runnable() { public void run() { //由于线程one先启动,下面这句话让它等一等线程two. 读着可根据自己电脑的实际性能适当调整等待时间. //shortWait(100000); a = 1; x = b; } }); Thread other = new Thread(new Runnable() { public void run() { b = 1; y = a; } }); one.start();other.start(); one.join();other.join(); String result = "第" + i + "次 (" + x + "," + y + ")"; if(x == 0 && y == 0) { System.err.println(result); break; } else { //System.out.println(result); } } } public static void shortWait(long interval){ long start = System.nanoTime(); long end; do{ end = System.nanoTime(); }while(start + interval >= end); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
# 系统底层如何实现数据一致性
- MESI如果能解决,就使用MESI
- 如果不能,就锁总线
# 系统底层如何保证有序性
- 内存屏障sfence mfence lfence等系统原语
- 锁总线
# volatile如何解决指令重排序
volatile i
ACC_VOLATILE
JVM的内存屏障
屏障两边的指令不可以重排!保障有序!
hotspot实现
bytecodeinterpreter.cpp
int field_offset = cache->f2_as_index(); if (cache->is_volatile()) { if (support_IRIW_for_not_multiple_copy_atomic_cpu) { OrderAccess::fence(); } }1
2
3
4
5
6orderaccess_linux_x86.inline.hpp
inline void OrderAccess::fence() { if (os::is_MP()) { // always use locked addl since mfence is sometimes expensive #ifdef AMD64 __asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory"); #else __asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory"); #endif } }1
2
3
4
5
6
7
8
9
10
# 用hsdis观察synchronized和volatile
安装hsdis (自行百度)
代码
public class T { public static volatile int i = 0; public static void main(String[] args) { for(int i=0; i<1000000; i++) { m(); n(); } } public static synchronized void m() { } public static void n() { i = 1; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19java -XX:+UnlockDiagnosticVMOptions -XX:+PrintAssembly T > 1.txt1输出结果
由于JIT会为所有代码生成汇编,请搜索T::m T::n,来找到m() 和 n()方法的汇编码
============================= C1-compiled nmethod ==============================
----------------------------------- Assembly -----------------------------------
Compiled method (c1) 67 1 3 java.lang.Object::<init> (1 bytes)
total in heap [0x00007f81d4d33010,0x00007f81d4d33360] = 848
relocation [0x00007f81d4d33170,0x00007f81d4d33198] = 40
main code [0x00007f81d4d331a0,0x00007f81d4d33260] = 192
stub code [0x00007f81d4d33260,0x00007f81d4d332f0] = 144
metadata [0x00007f81d4d332f0,0x00007f81d4d33300] = 16
scopes data [0x00007f81d4d33300,0x00007f81d4d33318] = 24
scopes pcs [0x00007f81d4d33318,0x00007f81d4d33358] = 64
dependencies [0x00007f81d4d33358,0x00007f81d4d33360] = 8
--------------------------------------------------------------------------------
[Constant Pool (empty)]
--------------------------------------------------------------------------------
[Deopt Handler Code]
0x00007f81d4d3a510: movabs $0x7f81d4d3a510,%r10 ; {section_word}
0x00007f81d4d3a51a: push %r10
0x00007f81d4d3a51c: jmpq 0x00007f81d47ed0a0 ; {runtime_call DeoptimizationBlob}
0x00007f81d4d3a521: hlt
0x00007f81d4d3a522: hlt
0x00007f81d4d3a523: hlt
0x00007f81d4d3a524: hlt
0x00007f81d4d3a525: hlt
0x00007f81d4d3a526: hlt
0x00007f81d4d3a527: hlt
--------------------------------------------------------------------------------
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 3.volatile不能保证原子性
volatile不能保证原子性,所以不能替代synchroized
# AtomicXXX
# LongAdder
# JUC同步工具
# CAS
Compare And Swap/Exchange
# ReentrantLock
API
- lock
- unlock
- tryLock
tryLock
lockInterruptibly
公平锁(默认为非公平锁)
new ReentrantLock(true)
如果获取锁的队列有数据,他就加入到队列中抢锁
Condition
针对一个Condition有一个等待队列
跟synchroized的区别
- cas vs sync
- synchroized只有非公平锁
- lock需要程序手动加锁、解锁,synchroized系统自动加锁、解锁
- lock可以出现不同的condition
# Condition等待与通知
# CountDownLatch
倒数门闩
api
- latch.countDown()
- latch.await()
用场景
- 等待其他进程结束
- 响应式编程
使用实例
package xyz.yowei.juc.c_020_juclocks; import org.junit.jupiter.api.Test; import java.util.concurrent.CountDownLatch; public class T06_TestCountDownLatch { public static void main(String[] args) { usingJoin(); usingCountDownLatch(); } private static void usingCountDownLatch() { Thread[] threads = new Thread[100]; CountDownLatch latch = new CountDownLatch(threads.length); for (int i = 0; i < threads.length; i++) { threads[i] = new Thread(() -> { int result = 0; for (int j = 0; j < 10000; j++) result += j; latch.countDown(); }); } for (int i = 0; i < threads.length; i++) { threads[i].start(); } try { latch.await(); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("end latch"); } private static void usingJoin() { Thread[] threads = new Thread[100]; for (int i = 0; i < threads.length; i++) { threads[i] = new Thread(() -> { int result = 0; for (int j = 0; j < 10000; j++) result += j; }); } for (int i = 0; i < threads.length; i++) { threads[i].start(); } for (int i = 0; i < threads.length; i++) { try { threads[i].join(); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println("end join"); } @Test public void testCountDown() { CountDownLatch latch = new CountDownLatch(3); System.out.println(latch.getCount()); latch.countDown(); System.out.println(latch.getCount()); latch.countDown(); System.out.println(latch.getCount()); latch.countDown(); System.out.println(latch.getCount()); latch.countDown(); System.out.println(latch.getCount()); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
# CyclicBarrier
线程栅栏
- API
public class TestCyclicBarrier {
public static void main(String[] args) {
//CyclicBarrier barrier = new CyclicBarrier(20);
CyclicBarrier barrier = new CyclicBarrier(20, () -> System.out.println("满人"));
/*CyclicBarrier barrier = new CyclicBarrier(20, new Runnable() {
@Override
public void run() {
System.out.println("满人,发车");
}
});*/
for (int i = 0; i < 100; i++) {
new Thread(() -> {
try {
barrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}).start();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
使用场景
针对一些复杂场景,某线程需要等待其他线程都执行完了之后才能继续执行。比如某操作需要访问数据库、网络、文件等操作同步执行。
# Phaser
阶段执行
用法
- extends Phaser类,重写onAdvance
Aapi
- arriveAndAwaitAdvance
- arriveAndDeregister
实例1
package xyz.yowei.juc.c_020_juclocks; import java.util.Random; import java.util.concurrent.Phaser; import java.util.concurrent.TimeUnit; public class T08_TestPhaser { static Random r = new Random(); static MarriagePhaser phaser = new MarriagePhaser(); static void milliSleep(int milli) { try { TimeUnit.MILLISECONDS.sleep(milli); } catch (InterruptedException e) { e.printStackTrace(); } } public static void main(String[] args) { phaser.bulkRegister(5); for (int i = 0; i < 5; i++) { final int nameIndex = i; new Thread(() -> { Person p = new Person("person " + nameIndex); p.arrive(); phaser.arriveAndAwaitAdvance(); p.eat(); phaser.arriveAndAwaitAdvance(); p.leave(); phaser.arriveAndAwaitAdvance(); }).start(); } } static class MarriagePhaser extends Phaser { @Override protected boolean onAdvance(int phase, int registeredParties) { switch (phase) { case 0: System.out.println("所有人都到齐了"); return false; case 1: System.out.println("所有人都吃完了"); return false; case 2: System.out.println("所有人都离开了"); System.out.println("婚礼结束"); return true; default: return true; } } } static class Person { String name; public Person(String name) { this.name = name; } public void arrive() { milliSleep(r.nextInt(1000)); System.out.printf("%s �����ֳ���\n", name); } public void eat() { milliSleep(r.nextInt(1000)); System.out.printf("%s ����!\n", name); } public void leave() { milliSleep(r.nextInt(1000)); System.out.printf("%s �뿪��\n", name); } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88实例2
package xyz.yowei.juc.c_020_juclocks; import java.util.Random; import java.util.concurrent.Phaser; import java.util.concurrent.TimeUnit; public class T09_TestPhaser2 { static Random r = new Random(); static MarriagePhaser phaser = new MarriagePhaser(); static void milliSleep(int milli) { try { TimeUnit.MILLISECONDS.sleep(milli); } catch (InterruptedException e) { e.printStackTrace(); } } public static void main(String[] args) { phaser.bulkRegister(7); for (int i = 0; i < 5; i++) { new Thread(new Person("p" + i)).start(); } new Thread(new Person("新郎")).start(); new Thread(new Person("新娘")).start(); } static class MarriagePhaser extends Phaser { @Override protected boolean onAdvance(int phase, int registeredParties) { switch (phase) { case 0: System.out.println("所有人都到齐了!" + registeredParties); System.out.println(); return false; case 1: System.out.println("所有人都吃完了!" + registeredParties); System.out.println(); return false; case 2: System.out.println("所有人都离开了!" + registeredParties); System.out.println(); return false; case 3: System.out.println("婚礼结束!新郎新娘抱抱!" + registeredParties); return true; default: return true; } } } static class Person implements Runnable { String name; public Person(String name) { this.name = name; } public void arrive() { milliSleep(r.nextInt(1000)); System.out.printf("%s 到达现场!\n", name); phaser.arriveAndAwaitAdvance(); } public void eat() { milliSleep(r.nextInt(1000)); System.out.printf("%s 吃完!\n", name); phaser.arriveAndAwaitAdvance(); } public void leave() { milliSleep(r.nextInt(1000)); System.out.printf("%s 离开!\n", name); phaser.arriveAndAwaitAdvance(); } private void hug() { if (name.equals("新郎") || name.equals("新娘")) { milliSleep(r.nextInt(1000)); System.out.printf("%s 洞房!\n", name); phaser.arriveAndAwaitAdvance(); } else { phaser.arriveAndDeregister(); //phaser.register() } } @Override public void run() { arrive(); eat(); leave(); hug(); } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
# ReadWriteLock
共享锁
读readLock
排他锁
写writeLock
实例
public class TestReadWriteLock { static Lock lock = new ReentrantLock(); private static int value; static ReadWriteLock readWriteLock = new ReentrantReadWriteLock(); static Lock readLock = readWriteLock.readLock(); static Lock writeLock = readWriteLock.writeLock(); public static void read(Lock lock) { lock.lock(); try { SleepHelper.sleepSeconds(1); System.out.println("read over!"); //模拟读取操作 } finally { lock.unlock(); } } public static void write(Lock lock, int v) { lock.lock(); try { SleepHelper.sleepSeconds(1); value = v; System.out.println("write over!"); //模拟写操作 } finally { lock.unlock(); } } public static void main(String[] args) { Runnable readR = () -> read(lock); //Runnable readR = ()-> read(readLock); Runnable writeR = () -> write(lock, new Random().nextInt()); //Runnable writeR = ()->write(writeLock, new Random().nextInt()); for (int i = 0; i < 18; i++) new Thread(readR).start(); for (int i = 0; i < 2; i++) new Thread(writeR).start(); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# Semaphore
信号灯
允许多少个线程同时执行,内部实现有队列
API
Semaphore s = new Semaphore(num);
Semaphore s = new Semaphore(num,fair); // fair是否公平
s.acquire(); //获取可执行的许可
s.release(); //释放占用的名额
使用场景
- 限流(车道和收费)
- 分批发短信
实例
package xyz.yowei.juc.c_020_juclocks; import java.util.concurrent.Semaphore; public class T11_TestSemaphore { public static void main(String[] args) { //Semaphore s = new Semaphore(2); Semaphore s = new Semaphore(2, true); //允许一个线程同时执行 //Semaphore s = new Semaphore(1); new Thread(() -> { try { s.acquire(); System.out.println("T1 running..."); Thread.sleep(200); System.out.println("T1 running..."); } catch (InterruptedException e) { e.printStackTrace(); } finally { s.release(); } }).start(); new Thread(() -> { try { s.acquire(); System.out.println("T2 running..."); Thread.sleep(200); System.out.println("T2 running..."); s.release(); } catch (InterruptedException e) { e.printStackTrace(); } }).start(); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# Exchanger
线程之间交换数据
API
实例
package xyz.yowei.juc.c_020_juclocks; import java.util.concurrent.Exchanger; public class T12_TestExchanger { static Exchanger<String> exchanger = new Exchanger<>(); public static void main(String[] args) { new Thread(() -> { String s = "T1"; try { s = exchanger.exchange(s); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + " " + s); }, "t1").start(); new Thread(() -> { String s = "T2"; try { s = exchanger.exchange(s); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + " " + s); }, "t2").start(); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# LockSupport
一个线程的工具类,所有的方法都是静态方法,可以让线程在任何位置阻塞,也可以在任何位置唤醒
API
LockSupport.park()
针对当前线程
LockSupport.park(Object blocker)
blocker是用来记录线程被阻塞时被谁阻塞的。用于线程监控和分析工具来定位原因的。
LockSupport.unpark(t) // 可以先于park调用
不会跑出Interrupt异常
对比wait/notify
- wait和notify都是Object中的方法,在调用这两个方法前必须先获得锁对象,但是park不需要获取某个对象的锁就可以锁住线程
- notify只能随机选择一个线程唤醒,无法唤醒指定的线程,unpark却可以唤醒一个指定的线程。
实例
package xyz.yowei.juc.c_020_juclocks; import java.util.concurrent.TimeUnit; import java.util.concurrent.locks.LockSupport; public class T13_TestLockSupport { public static void main(String[] args) { Thread t = new Thread(() -> { for (int i = 0; i < 10; i++) { System.out.println(i); if (i == 5) { LockSupport.park(); } try { TimeUnit.SECONDS.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); } } }); t.start(); //LockSupport.unpark(t); try { TimeUnit.SECONDS.sleep(8); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println("after 8 senconds!"); LockSupport.unpark(t); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# AQS(CLH)
# varHandle
普通变量也能使用原子操作
比反射快,可以理解成直接操作二进制码
# ThreadLocal
线程独有的
调用set的时候是放在currentThread的map里面,这个map是线程独有的
使用场景
Spring的声明式事物
# Java的四种引用
强引用
普通的引用,普通引用如果一直存在,引用的对象是不会被gc回收的
public class NormalReference { public static void main(String[] args) throws IOException { M m = new M(); //m = null; System.gc(); //DisableExplicitGC System.out.println(m); System.in.read();//阻塞main线程,给垃圾回收线程时间执行 } }1
2
3
4
5
6
7
8
9
10
软引用
当内存不够用的时候才会回收
应用场景:做缓存用
-Xms 20M -Xmx20M
public class SoftReference { public static void main(String[] args) { SoftReference<byte[]> m = new SoftReference<>(new byte[1024 * 1024 * 10]); //m = null; System.out.println(m.get()); System.gc(); try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(m.get()); //再分配一个数组,heap将装不下,这时候系统会垃圾回收,先回收一次,如果不够,会把软引用干掉 byte[] b = new byte[1024 * 1024 * 12]; System.out.println(m.get()); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18弱引用
只要有垃圾回收就会被回收
使用场景:一般用在容器,WeakHashMap
JDK中的使用:ThreadLocal中map的key是弱引用指向threadLocal的,如果使用强引用会造成内存泄露
使用完ThreadLocal之后一定要remove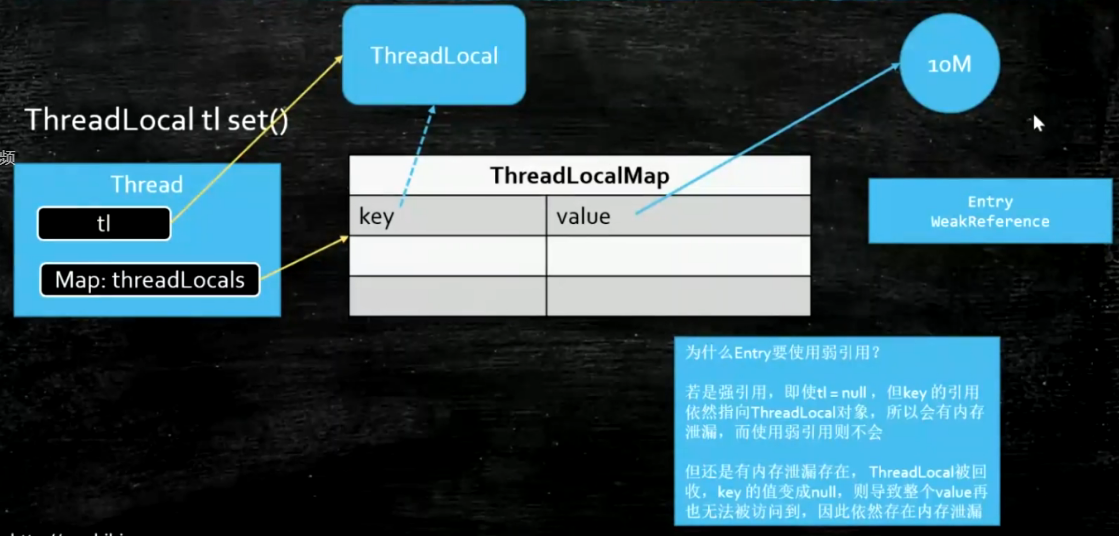
public class WeakReference { public static void main(String[] args) { WeakReference<M> m = new WeakReference<>(new M()); System.out.println(m.get()); System.gc(); SleepHelper.sleepSeconds(1); System.out.println(m.get()); /*ThreadLocal<M> tl = new ThreadLocal<>(); tl.set(new M()); tl.remove();*/ } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15虚引用
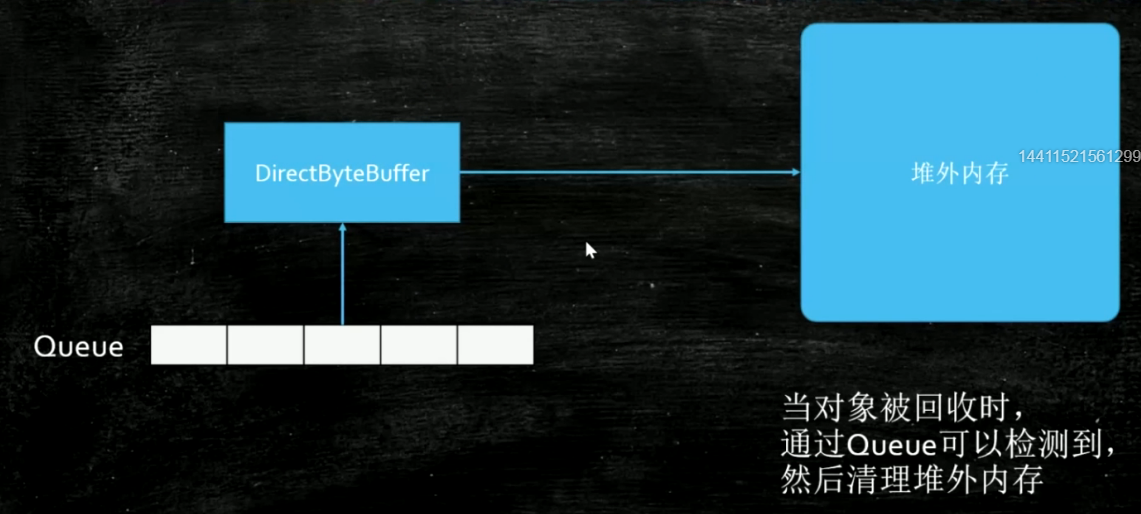
主要设计了给开发虚拟机的人使用的,使用场景:管理堆外内存
垃圾回收一看见就会回收,即使是有强引用在引用
get变量的值也是get不到的,主要使用的是GC在回收的时候回想一个队列中放入一个通知
public class T04_PhantomReference {
private static final List<Object> LIST = new LinkedList<>();
private static final ReferenceQueue<M> QUEUE = new ReferenceQueue<>();
public static void main(String[] args) {
PhantomReference<M> phantomReference = new PhantomReference<>(new M(), QUEUE);
System.out.println(phantomReference.get());
ByteBuffer b = ByteBuffer.allocateDirect(1024);
new Thread(() -> {
while (true) {
LIST.add(new byte[1024 * 1024]);
SleepHelper.sleepSeconds(1);
System.out.println(phantomReference.get());
}
}).start();
//垃圾回收线程
new Thread(() -> {
while (true) {
Reference<? extends M> poll = QUEUE.poll();
if (poll != null) {
System.out.println("--- 虚引用对象被jvm回收了 ---- " + poll);
}
}
}).start();
SleepHelper.sleepSeconds(1);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 容器
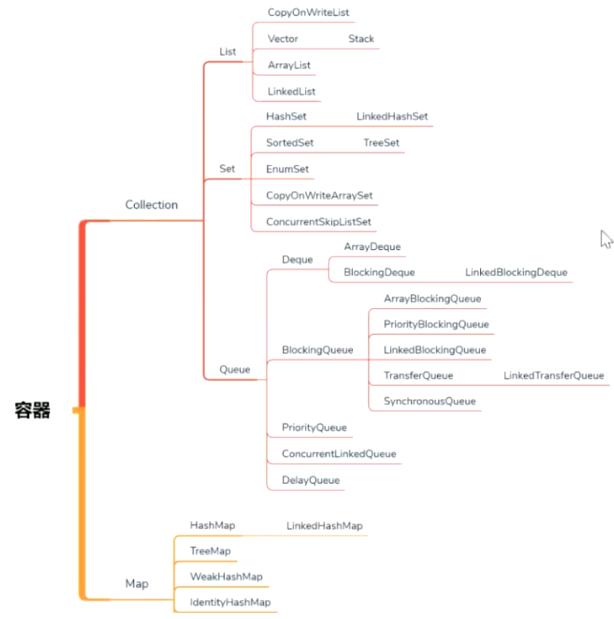
# 演进历程
JDK1.0的时候只有Hashtable和Vector这两个容器类,这两个自带锁,线程安全。现在基本不用
Hashtable->ConcurrentHashMap
Hashtable->HashMap->Collections.SynchroizedHashMap->ConcurrentHashMap
Vector->Queue
Queue和List的区别
Queue添加了对线程友好的API (offer peek poll)
# Collection
# List
- CopyOnWriteList
# Set
# Queue
LinkedBlockingQueue
DelayQueue
按照时间进行优先级排序
使用场景:按照时间进行任务调度
PriorityQueue
内部二叉树排序
SynchroizedQueue
这里面的Queue实际上是不存在的,等着传递数据
使用场景:
TransferQueue
API
transfer(o)
放入数据之后等着消费者消费才会返回
使用场景:确认订单有人处理再反馈
pub(o)
放入数据就返回了
# Map
ConcurrentHashMap
TreeMap
ConcurrentSkipListMap
跳表
# 线程池
# Executor
一个接口
把线程的定义和线程的执行分开,Executor负责执行
# ExecutorService
AbstractExecutorService
# 相关API
- Callable
- Future
- FutureTask
- CompletableFuture
# ThreadPoolExecutor

线程的集合
任务的集合
# 七个参数
corePoolSize
核心线程数,线程池中长期活跃的线程数
maximumPoolSize
线程池中最大产生的线程数
如何评估线程池线程数
线程数多会相互竞争稀缺的处理器和内存资源,浪费大量的时间再上下文切换上
线程数少处理器的核就无法充分利用
《Java并发编程实战》中作者建议线程池大小与处理器的利用率之比可以使用下面的公式进行估算。**最终还是要以压测的结果为准 **

keepAliveTime
空闲线程存活时间
TImeUnit
keepAliveTime的单位
BlockingQueue
任务队列
ThreadFactory
线程工厂,可以自定义产生线程的方法,对线程进行安全检查并命名,Executors.defaultThreadFactory有默认实现
DiscardPolicy
- 拒绝策略,线程都忙,任务队列也满了根据拒绝策略拒绝任务。jdk默认提供了4中策略,可以自定义
Abort
抛异常
Discard
扔掉,不抛异常
DiscardOldest
扔掉排队时间最久的
CallerRuns
调用者处理任务
为什么阿里手册中不建议使用jdk自带的创建线程池的方法
- 任务队列的最大长度是Integer.MAX_VALUE,可能会造成内存溢出
- 需要根据业务自定义拒绝策略
- 需要自定义线程名称,出现问题方便查询问题
如何自定义拒绝策略
实现RejectedExecutionHandler接口
- 拒绝策略,线程都忙,任务队列也满了根据拒绝策略拒绝任务。jdk默认提供了4中策略,可以自定义
# 源码解析
# 1、常用变量的解释
// 1. `ctl`,可以看做一个int类型的数字,高3位表示线程池状态,低29位表示worker数量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 2. `COUNT_BITS`,`Integer.SIZE`为32,所以`COUNT_BITS`为29
private static final int COUNT_BITS = Integer.SIZE - 3;
// 3. `CAPACITY`,线程池允许的最大线程数。1左移29位,然后减1,即为 2^29 - 1
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
// 4. 线程池有5种状态,按大小排序如下:RUNNING < SHUTDOWN < STOP < TIDYING < TERMINATED
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
// 5. `runStateOf()`,获取线程池状态,通过按位与操作,低29位将全部变成0
private static int runStateOf(int c) { return c & ~CAPACITY; }
// 6. `workerCountOf()`,获取线程池worker数量,通过按位与操作,高3位将全部变成0
private static int workerCountOf(int c) { return c & CAPACITY; }
// 7. `ctlOf()`,根据线程池状态和线程池worker数量,生成ctl值
private static int ctlOf(int rs, int wc) { return rs | wc; }
/*
* Bit field accessors that don't require unpacking ctl.
* These depend on the bit layout and on workerCount being never negative.
*/
// 8. `runStateLessThan()`,线程池状态小于xx
private static boolean runStateLessThan(int c, int s) {
return c < s;
}
// 9. `runStateAtLeast()`,线程池状态大于等于xx
private static boolean runStateAtLeast(int c, int s) {
return c >= s;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 2、构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
// 基本类型参数校验
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
// 空指针校验
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
// 根据传入参数`unit`和`keepAliveTime`,将存活时间转换为纳秒存到变量`keepAliveTime `中
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# 3、提交执行task的过程
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
int c = ctl.get();
// worker数量比核心线程数小,直接创建worker执行任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// worker数量超过核心线程数,任务直接进入队列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 线程池状态不是RUNNING状态,说明执行过shutdown命令,需要对新加入的任务执行reject()操作。
// 这儿为什么需要recheck,是因为任务入队列前后,线程池的状态可能会发生变化。
if (! isRunning(recheck) && remove(command))
reject(command);
// 这儿为什么需要判断0值,主要是在线程池构造方法中,核心线程数允许为0
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 如果线程池不是运行状态,或者任务进入队列失败,则尝试创建worker执行任务。
// 这儿有3点需要注意:
// 1. 线程池不是运行状态时,addWorker内部会判断线程池状态
// 2. addWorker第2个参数表示是否创建核心线程
// 3. addWorker返回false,则说明任务执行失败,需要执行reject操作
else if (!addWorker(command, false))
reject(command);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
# 4、addworker源码解析
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
// 外层自旋
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 这个条件写得比较难懂,我对其进行了调整,和下面的条件等价
// (rs > SHUTDOWN) ||
// (rs == SHUTDOWN && firstTask != null) ||
// (rs == SHUTDOWN && workQueue.isEmpty())
// 1. 线程池状态大于SHUTDOWN时,直接返回false
// 2. 线程池状态等于SHUTDOWN,且firstTask不为null,直接返回false
// 3. 线程池状态等于SHUTDOWN,且队列为空,直接返回false
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
// 内层自旋
for (;;) {
int wc = workerCountOf(c);
// worker数量超过容量,直接返回false
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 使用CAS的方式增加worker数量。
// 若增加成功,则直接跳出外层循环进入到第二部分
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
// 线程池状态发生变化,对外层循环进行自旋
if (runStateOf(c) != rs)
continue retry;
// 其他情况,直接内层循环进行自旋即可
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
// worker的添加必须是串行的,因此需要加锁
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
// 这儿需要重新检查线程池状态
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
// worker已经调用过了start()方法,则不再创建worker
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
// worker创建并添加到workers成功
workers.add(w);
// 更新`largestPoolSize`变量
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// 启动worker线程
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
// worker线程启动失败,说明线程池状态发生了变化(关闭操作被执行),需要进行shutdown相关操作
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
# 5、线程池worker任务单元
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* This class will never be serialized, but we provide a
* serialVersionUID to suppress a javac warning.
*/
private static final long serialVersionUID = 6138294804551838833L;
/** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
/**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
// 这儿是Worker的关键所在,使用了线程工厂创建了一个线程。传入的参数为当前worker
this.thread = getThreadFactory().newThread(this);
}
/** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
// 省略代码...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 6、核心线程执行逻辑-runworker
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
// 调用unlock()是为了让外部可以中断
w.unlock(); // allow interrupts
// 这个变量用于判断是否进入过自旋(while循环)
boolean completedAbruptly = true;
try {
// 这儿是自旋
// 1. 如果firstTask不为null,则执行firstTask;
// 2. 如果firstTask为null,则调用getTask()从队列获取任务。
// 3. 阻塞队列的特性就是:当队列为空时,当前线程会被阻塞等待
while (task != null || (task = getTask()) != null) {
// 这儿对worker进行加锁,是为了达到下面的目的
// 1. 降低锁范围,提升性能
// 2. 保证每个worker执行的任务是串行的
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
// 如果线程池正在停止,则对当前线程进行中断操作
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
// 执行任务,且在执行前后通过`beforeExecute()`和`afterExecute()`来扩展其功能。
// 这两个方法在当前类里面为空实现。
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
// 帮助gc
task = null;
// 已完成任务数加一
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
// 自旋操作被退出,说明线程池正在结束
processWorkerExit(w, completedAbruptly);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
# 线程池状态
线程池有5种状态,按大小排序如下:RUNNING < SHUTDOWN < STOP < TIDYING < TERMINATED
private static final int RUNNING = -1 << COUNT_BITS; private static final int SHUTDOWN = 0 << COUNT_BITS; private static final int STOP = 1 << COUNT_BITS; private static final int TIDYING = 2 << COUNT_BITS; private static final int TERMINATED = 3 << COUNT_BITS;1
2
3
4
5
# Executors
线程池的工厂
newSingleThreadPool
new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())1为什么要用单例的?
线程池有任务队列
生命周期管理
保证任务执行顺序
newCachedThreadPool
new ThreadPoolExecutor(0, Integer.MAX_VALUE,60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>())1任务队列为SynchronousQueue,也就是说来一个任务就等到线程池安排线程来处理。如果现有线程都在忙就直接new一个新线程来处理任务。
newFixedThreadPool
new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())1任务队列为LinkedBlockingQueue,固定线程数的线程池
newScheduledThreadPool
new ThreadPoolExecutor(corePoolSize, Integer.MAX_VALUE, 0L, NANOSECONDS, DelayedWorkQueue workQueue, Executors.defaultThreadFactory(), defaultHandler)1任务队列为DelayedWorkQueue,定时任务线程池。
可以直接用线程池框架quartz、cron
面试:加入提供一个闹钟服务,订阅这个服务的人比较多,10亿人,怎么优化
分发到边缘节点中(线程池+队列)
newSingleThreadScheduledExecutor
new ScheduledThreadPoolExecutor(1)1
# 并发和并行的区别
并发指任务提交,并行指任务执行
并行是并发的子集(并发可以单个CPU,并行是多个CPU通吃执行)
# ForkJoinPool
特点
- 每个线程都维护了自己的一个任务队列,自己队列任务执行完了可以从别的队列steal
- 适用于一个大的任务拆分成一个一个小的任务来执行
- 用很少的线程可以执行很多的任务(自任务)TPE做不到先执行自任务
- CPU密集型
实例
package xyz.yowei.juc.c_026_01_ThreadPool; import java.io.IOException; import java.util.Arrays; import java.util.Random; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.RecursiveAction; import java.util.concurrent.RecursiveTask; public class T12_ForkJoinPool { static int[] nums = new int[1000000]; static final int MAX_NUM = 50000; static Random r = new Random(); static { for (int i = 0; i < nums.length; i++) { nums[i] = r.nextInt(100); } System.out.println("---" + Arrays.stream(nums).sum()); //stream api } static class AddTask extends RecursiveAction { int start, end; AddTask(int s, int e) { start = s; end = e; } @Override protected void compute() { if (end - start <= MAX_NUM) { long sum = 0L; for (int i = start; i < end; i++) sum += nums[i]; System.out.println("from:" + start + " to:" + end + " = " + sum); } else { int middle = start + (end - start) / 2; AddTask subTask1 = new AddTask(start, middle); AddTask subTask2 = new AddTask(middle, end); subTask1.fork(); subTask2.fork(); } } } static class AddTaskRet extends RecursiveTask<Long> { private static final long serialVersionUID = 1L; int start, end; AddTaskRet(int s, int e) { start = s; end = e; } @Override protected Long compute() { if (end - start <= MAX_NUM) { long sum = 0L; for (int i = start; i < end; i++) sum += nums[i]; return sum; } int middle = start + (end - start) / 2; AddTaskRet subTask1 = new AddTaskRet(start, middle); AddTaskRet subTask2 = new AddTaskRet(middle, end); subTask1.fork(); subTask2.fork(); return subTask1.join() + subTask2.join(); } } public static void main(String[] args) throws IOException { /*ForkJoinPool fjp = new ForkJoinPool(); AddTask task = new AddTask(0, nums.length); fjp.execute(task);*/ T12_ForkJoinPool temp = new T12_ForkJoinPool(); ForkJoinPool fjp = new ForkJoinPool(); AddTaskRet task = new AddTaskRet(0, nums.length); fjp.execute(task); long result = task.join(); System.out.println(result); //System.in.read(); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
# WorkStealingPool

WorkStealingQueue
分叉再汇总
# JMH
# 什么是JMH
Java准测试工具套件
Java Microbenchmark Harness
2013年首发,由JIT的开发人员开发,归于OpenJDK
# 官网
http://openjdk.java.net/projects/code-tools/jmh/
# 创建JMH测试
创建Maven项目,添加依赖
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <encoding>UTF-8</encoding> <java.version>1.8</java.version> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> </properties> <groupId>mashibing.com</groupId> <artifactId>HelloJMH2</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <!-- https://mvnrepository.com/artifact/org.openjdk.jmh/jmh-core --> <dependency> <groupId>org.openjdk.jmh</groupId> <artifactId>jmh-core</artifactId> <version>1.21</version> </dependency> <!-- https://mvnrepository.com/artifact/org.openjdk.jmh/jmh-generator-annprocess --> <dependency> <groupId>org.openjdk.jmh</groupId> <artifactId>jmh-generator-annprocess</artifactId> <version>1.21</version> <scope>test</scope> </dependency> </dependencies> </project>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38idea安装JMH插件 JMH plugin v1.0.3
由于用到了注解,打开运行程序注解配置
compiler -> Annotation Processors -> Enable Annotation Processing
定义需要测试类PS (ParallelStream)
package com.mashibing.jmh; import java.util.ArrayList; import java.util.List; import java.util.Random; public class PS { static List<Integer> nums = new ArrayList<>(); static { Random r = new Random(); for (int i = 0; i < 10000; i++) nums.add(1000000 + r.nextInt(1000000)); } static void foreach() { nums.forEach(v->isPrime(v)); } static void parallel() { nums.parallelStream().forEach(PS::isPrime); } static boolean isPrime(int num) { for(int i=2; i<=num/2; i++) { if(num % i == 0) return false; } return true; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29写单元测试
这个测试类一定要在test package下面
package com.mashibing.jmh; import org.openjdk.jmh.annotations.Benchmark; import static org.junit.jupiter.api.Assertions.*; public class PSTest { @Benchmark public void testForEach() { PS.foreach(); } }1
2
3
4
5
6
7
8
9
10
11
12运行测试类,如果遇到下面的错误:
ERROR: org.openjdk.jmh.runner.RunnerException: ERROR: Exception while trying to acquire the JMH lock (C:\WINDOWS\/jmh.lock): C:\WINDOWS\jmh.lock (拒绝访问。), exiting. Use -Djmh.ignoreLock=true to forcefully continue. at org.openjdk.jmh.runner.Runner.run(Runner.java:216) at org.openjdk.jmh.Main.main(Main.java:71)1
2
3这个错误是因为JMH运行需要访问系统的TMP目录,解决办法是:
打开RunConfiguration -> Environment Variables -> include system environment viables,这样就不会存放在Windows目录中了
阅读测试报告
# JMH中的基本概念
Warmup 预热,由于JVM中对于特定代码会存在优化(本地化),预热对于测试结果很重要
fork(5)
起多少个线程执行
Mesurement 总共执行多少次测试
Timeout
Threads 线程数,由fork指定
Benchmark mode
基准测试的模式(Mode.Throughput 吞吐量...)
Benchmark 测试哪一段代码
# Next
官方样例: http://hg.openjdk.java.net/code-tools/jmh/file/tip/jmh-samples/src/main/java/org/openjdk/jmh/samples/
# Disruptor
作者:马士兵 http://www.mashibing.com
最近更新:2019年10月22日
# 介绍
参考文献
- 主页:http://lmax-exchange.github.io/disruptor/
- 源码:https://github.com/LMAX-Exchange/disruptor
- GettingStarted: https://github.com/LMAX-Exchange/disruptor/wiki/Getting-Started
- api: http://lmax-exchange.github.io/disruptor/docs/index.html
- maven: https://mvnrepository.com/artifact/com.lmax/disruptor
disruptor - 分裂、瓦解
一个线程中每秒处理600万订单
2011年Duke奖
速度最快的MQ
性能极高,无锁cas,单机支持高并发
内存运行
# Disruptor的特点
对比ConcurrentLinkedQueue : 链表实现,数组的遍历更快
JDK中没有ConcurrentArrayQueue,因为数组的大小是固定的,如果要扩展需要拷贝到新数组中
Disruptor是数组实现的,头尾相连的数组
无锁,高并发,使用环形Buffer,直接覆盖(不用清除)旧的数据,降低GC频率
实现了基于事件的生产者消费者模式(观察者模式)
# RingBuffer

环形队列
RingBuffer的序号,指向下一个可用的元素
采用数组实现,没有首尾指针
对比ConcurrentLinkedQueue,用数组实现的速度更快
假如长度为8,当添加到第12个元素的时候在哪个序号上呢?用12%8决定
当Buffer被填满的时候到底是覆盖还是等待,由Producer决定
长度设为2的n次幂,利于二进制计算,例如:12%8 = 12 & (8 - 1) pos = num & (size -1)
# Disruptor开发步骤
定义Event - 队列中需要处理的元素
定义Event工厂,用于填充队列
这里牵扯到效率问题:disruptor初始化的时候,会调用Event工厂,对ringBuffer进行内存的提前分配,新的任务来的时候直接修改现有对象的值,不用new对象,GC产频率会降低
定义EventHandler(消费者),处理容器中的元素
# 事件发布模板
long sequence = ringBuffer.next(); // Grab the next sequence
try {
LongEvent event = ringBuffer.get(sequence); // Get the entry in the Disruptor
// for the sequence
event.set(8888L); // Fill with data
} finally {
ringBuffer.publish(sequence);
}
2
3
4
5
6
7
8
# 使用EventTranslator发布事件
//===============================================================
EventTranslator<LongEvent> translator1 = new EventTranslator<LongEvent>() {
@Override
public void translateTo(LongEvent event, long sequence) {
event.set(8888L);
}
};
ringBuffer.publishEvent(translator1);
//===============================================================
EventTranslatorOneArg<LongEvent, Long> translator2 = new EventTranslatorOneArg<LongEvent, Long>() {
@Override
public void translateTo(LongEvent event, long sequence, Long l) {
event.set(l);
}
};
ringBuffer.publishEvent(translator2, 7777L);
//===============================================================
EventTranslatorTwoArg<LongEvent, Long, Long> translator3 = new EventTranslatorTwoArg<LongEvent, Long, Long>() {
@Override
public void translateTo(LongEvent event, long sequence, Long l1, Long l2) {
event.set(l1 + l2);
}
};
ringBuffer.publishEvent(translator3, 10000L, 10000L);
//===============================================================
EventTranslatorThreeArg<LongEvent, Long, Long, Long> translator4 = new EventTranslatorThreeArg<LongEvent, Long, Long, Long>() {
@Override
public void translateTo(LongEvent event, long sequence, Long l1, Long l2, Long l3) {
event.set(l1 + l2 + l3);
}
};
ringBuffer.publishEvent(translator4, 10000L, 10000L, 1000L);
//===============================================================
EventTranslatorVararg<LongEvent> translator5 = new EventTranslatorVararg<LongEvent>() {
@Override
public void translateTo(LongEvent event, long sequence, Object... objects) {
long result = 0;
for(Object o : objects) {
long l = (Long)o;
result += l;
}
event.set(result);
}
};
ringBuffer.publishEvent(translator5, 10000L, 10000L, 10000L, 10000L);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
# 使用Lamda表达式
package com.mashibing.disruptor;
import com.lmax.disruptor.RingBuffer;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.util.DaemonThreadFactory;
public class Main03
{
public static void main(String[] args) throws Exception
{
// Specify the size of the ring buffer, must be power of 2.
int bufferSize = 1024;
// Construct the Disruptor
Disruptor<LongEvent> disruptor = new Disruptor<>(LongEvent::new, bufferSize, DaemonThreadFactory.INSTANCE);
// Connect the handler
disruptor.handleEventsWith((event, sequence, endOfBatch) -> System.out.println("Event: " + event));
// Start the Disruptor, starts all threads running
disruptor.start();
// Get the ring buffer from the Disruptor to be used for publishing.
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
ringBuffer.publishEvent((event, sequence) -> event.set(10000L));
System.in.read();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# ProducerType生产者线程模式
ProducerType有两种模式 Producer.MULTI和Producer.SINGLE
默认是MULTI,表示在多线程模式下产生sequence
如果确认是单线程生产者,那么可以指定SINGLE,效率会提升
如果是多个生产者(多线程),但模式指定为SINGLE,会出什么问题呢?
# 等待策略
1,(常用)BlockingWaitStrategy:通过线程阻塞的方式,等待生产者唤醒,被唤醒后,再循环检查依赖的sequence是否已经消费。
2,BusySpinWaitStrategy:线程一直自旋等待,可能比较耗cpu
3,LiteBlockingWaitStrategy:线程阻塞等待生产者唤醒,与BlockingWaitStrategy相比,区别在signalNeeded.getAndSet,如果两个线程同时访问一个访问waitfor,一个访问signalAll时,可以减少lock加锁次数.
4,LiteTimeoutBlockingWaitStrategy:与LiteBlockingWaitStrategy相比,设置了阻塞时间,超过时间后抛异常。
5,PhasedBackoffWaitStrategy:根据时间参数和传入的等待策略来决定使用哪种等待策略
6,TimeoutBlockingWaitStrategy:相对于BlockingWaitStrategy来说,设置了等待时间,超过后抛异常
7,(常用)YieldingWaitStrategy:尝试100次,然后Thread.yield()让出cpu
- (常用)SleepingWaitStrategy : sleep
# 消费者异常处理
默认:disruptor.setDefaultExceptionHandler()
覆盖:disruptor.handleExceptionFor().with()
# 依赖处理
# 经典面试题
- 两个线程轮流输出字符
- 思路
- 控制线程的状态(wait / running)
- 控制开关(循环检查开关)
- 锁
- 工具
- LockSupport
- CAS
- BlockingQueue
- AtomicInteger
- sync_wait_notify
- lock_condition
- 思路