# 概述
# 官网
https://zookeeper.apache.org/
分布式协调服务
Zookeeper比较简单,提供了很多原语,但是我们可以用这些简单的原语构建高级别的服务
# 设计的目标
simple
数据保存在内存中
Zookeeper的实现非常重视 高性能、高可用、严格有序的访问。
replicated
- 主从集群
- 最终一致性(过半写成功)
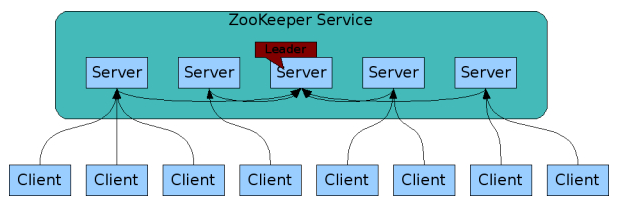
主单点故障问题
通常:主挂了->服务不可用->不可靠的集群
但实事zk是高可用的集群,如果leader一旦挂了,zk可以快速选举出一个可用的leader
leader挂掉的时候是无主模型,不可用的状态
不可用状态到可用状态的时间
官方压测不到200毫秒
ordered
fast
读写分离,内存运行
# 特性
数据模型和分层命名空间
Zookeeper提供的名称空间非常类似于标准的文件系统。名称由斜杠(/)分隔的路径元素序列。Zookeeper名称空间中的每个节点都由路径标识
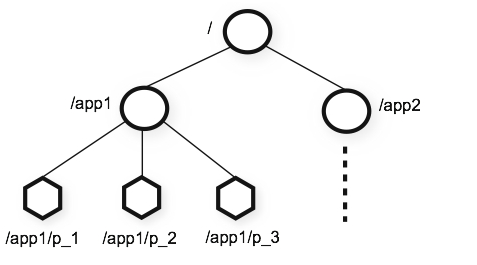
目录结构树
节点
- 每个节点可以存1M的数据,并且存储数据是二进制安全的
- 节点分持久节点和临时节点
- 临时节点
- 依赖于session创建节点,session消失节点也消失了
- 用于分布式锁,session的过期时间
- 一个客户端连接进来创建一个session,连接断开会销毁session,创建和销毁都会触发事务,事务id会+1
- session也是统一视图,会同步到其他节点,如果一个客户端断开连接,在session超时之前连接进来时可以继续操作的。
- 临时节点
- 序列节点
有条件的updates和watchs
Guarantees 保证
顺序一致性
客户端的更新将按照发送顺序应用,leader单点来写,维护顺序,顺序cZxid
原子性
更新成功或者失败,没有部分状态
单系统映像
无论客户端连接哪个服务器,客户端都将看到相同的服务视图
可靠性
持久性,一旦应用了更新,它将从那时起持续到客户端覆盖更新
及时性
最终一致性
# 用途
# 统一配置管理
每个节点可以存储1M的数据
# 统一命名
sequential
# 分布式同步
临时节点
分布式锁
锁依托一个负节点,且具备-s,代表父节点下可以有多把锁,队列式事务的锁
HA,选主
# 分组管理
path路径结构
# 搭建配置
安装jdk,并设置JAVA_HOME环境变量
下载
wget https://mirrors.bfsu.edu.cn/apache/zookeeper/zookeeper-3.5.9/apache-zookeeper-3.5.9-bin.tar.gz1解压
tar -zxvf apache-zookeeper-3.5.9-bin.tar.gz -C /tmp/ mv /tmp/apache-zookeeper-3.5.9-bin /opt/zookeeper-3.5.91
2配置环境变量
vi /etc/profile1追加如下行
export ZOOKEEPER_HOME=/opt/zookeeper-3.5.9 export PATH=$PATH:$ZOOKEEPER_HOME/bin1
2配置参数
cd zookeeper/conf #从模板拷贝配置文件 cp zoo.sample.cfg zoo.cfg #修改配置文件 vi zoo.cfg #创建持久化数据目录 mkdir /var/lib/zookeeper1
2
3
4
5
6
7datadir=/var/lib/zookeeper server.1=node01:2888:3888 server.2=node02:2888:38881
2
3
4配置myid
持久化数据目录中需要创建一个名为myid的文件,记录自己的编号(server.1=node01:2888:3888 中的1)
cd /var/zookeeper echo 1>myid1
2启动
#后台运行 zkServer.sh start #控制台运行 zkServer.sh start-foreground1
2
3
4
# 配置详解
tickTime
实例的心跳,发送心跳的频率
initLimit
初始化延迟,就是一个实例初始化的时候主实例可以忍耐从实例的一个延迟时间,这里配置的是tickTime的倍数。超过这个时间就回认为有问题
syncLimit
从节点消息反馈的时间,超过这个时间就会认为有问题。同样是tickTime的倍数
dataDir
持久化数据的目录
clientPort
服务的端口号
maxClientCnxns
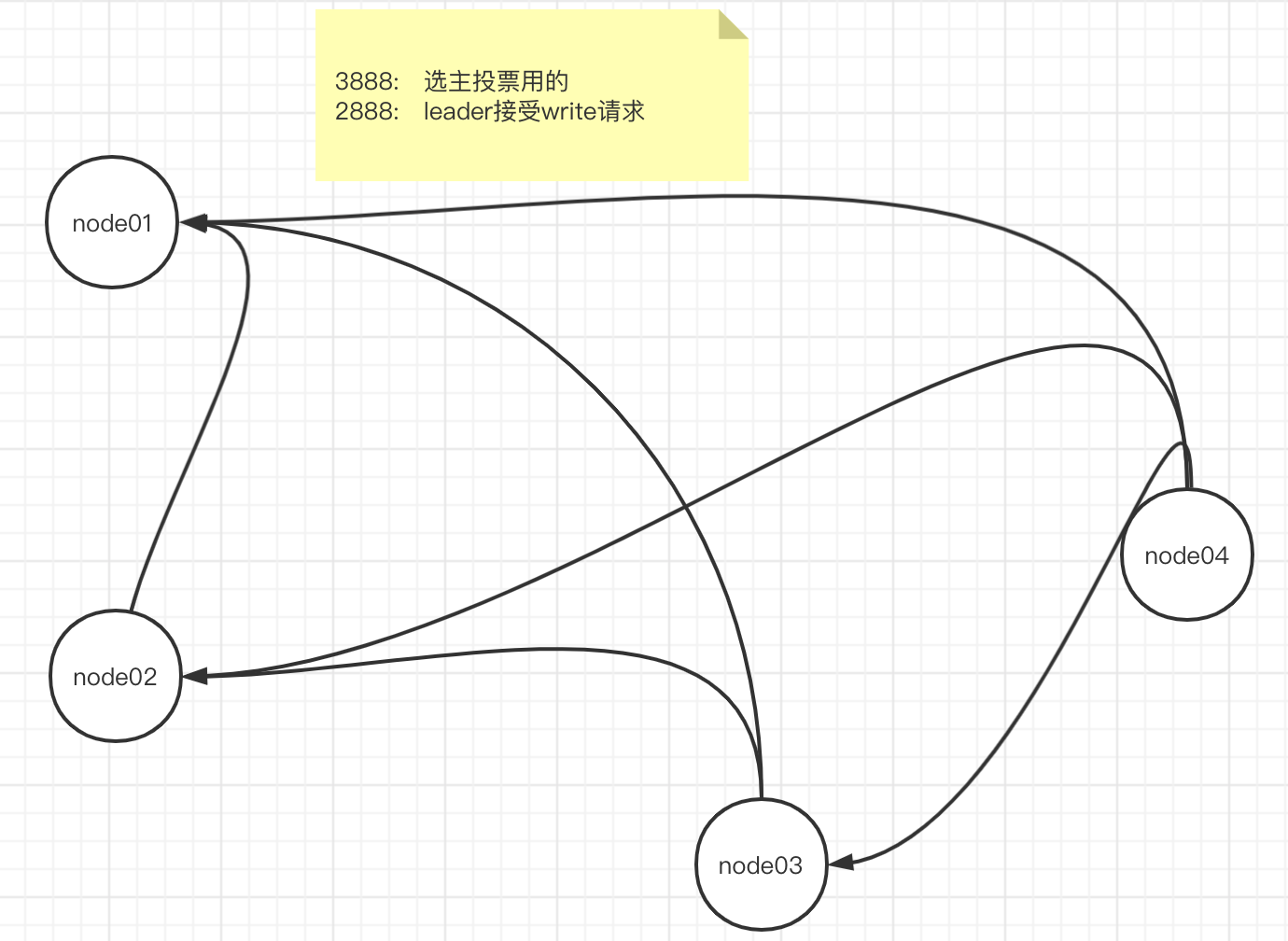
server
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
这里配置有两个端口号,2888用于正常情况下业务通信,3888用于投票选主
# 使用
# 维护命令
zkServer.sh start-foreground
zkServer.sh status
zkCli.sh
# 操作命令
help
create
[-s]
序列存储,会在key后面追加一组序列,用于分布式系统中往同一个目录中存值,规避覆盖问题
分布式情况下的统一命名
# 数据信息
cZxid
创建时的事务Id,64位,前32位表示纪元(不同主机做leader会不同),后32位表示事务id
ctime
创建时间
mZxid
修改的事务id
mtime
修改的时间
pZxid
当前节点下,创建的最后一个节点对应的事务id
ephemeralOwner
# 原理
# Paxos
https://www.douban.com/note/208430424/
# 概述
基于消息传递的一致性算法
Google的Chubby、Zookeeper都是基于Paxos的理论来实现的
被认为是目前为止唯一的分布式一致性算法
有一个前提:没有拜占庭将军问题
就是说Paxos只有在一个可信任的计算环境中才能成立,这个环境是不会被入侵所破坏的
# 小岛的故事
角色类比
- 小岛——ZK Server Cluster
- 议员——ZK Server
- 提议——ZNode Change(Create/Delete/SetData ...)
- 提议编号——Zxid(Zookeeper Transaction Id)
- 正式法令——所有ZNode及数据
- 总统——ZK Server Leader
问题
Client到Server端get一个数据,Server会取自己记录的数据返回给client并且告诉client自己的数据可能不是最新的,如果要最新的调用sync自己取同步一份最新的
Client到Server端修改一个数据,Server会将请求转到Leader,由Leader发起同步到各个节点,如果过半就记录成功就修改自己的值,并且
Leader挂了
其他Follower联系不上Leader会各自发表声明,推选新的总统,总统大选期间政府停业,拒绝屁民请求
# ZAB
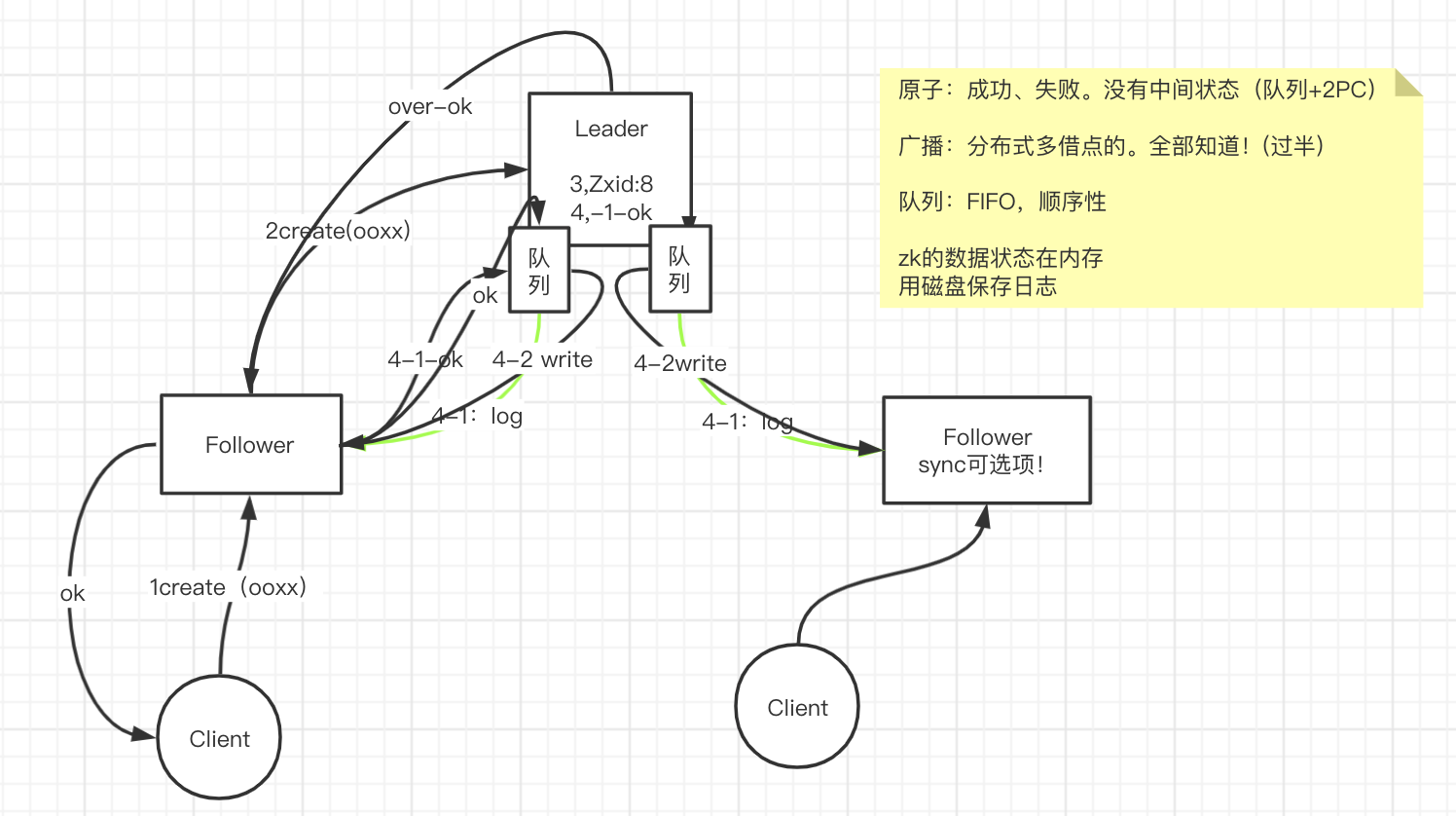
原子广播协议
- 原子:成功、失败,没有中间状态
- 队列+两阶段提交
- 广播:分布式多节点的,不确定每个节点都知道
- 过半通过
- 原子:成功、失败,没有中间状态
作用在可用状态,有Leader时
队列
- FIFO,顺序性
流程
# Leader选举
# 场景
- 第一次启动集群
- 重启集群,Leader挂了
# 流程
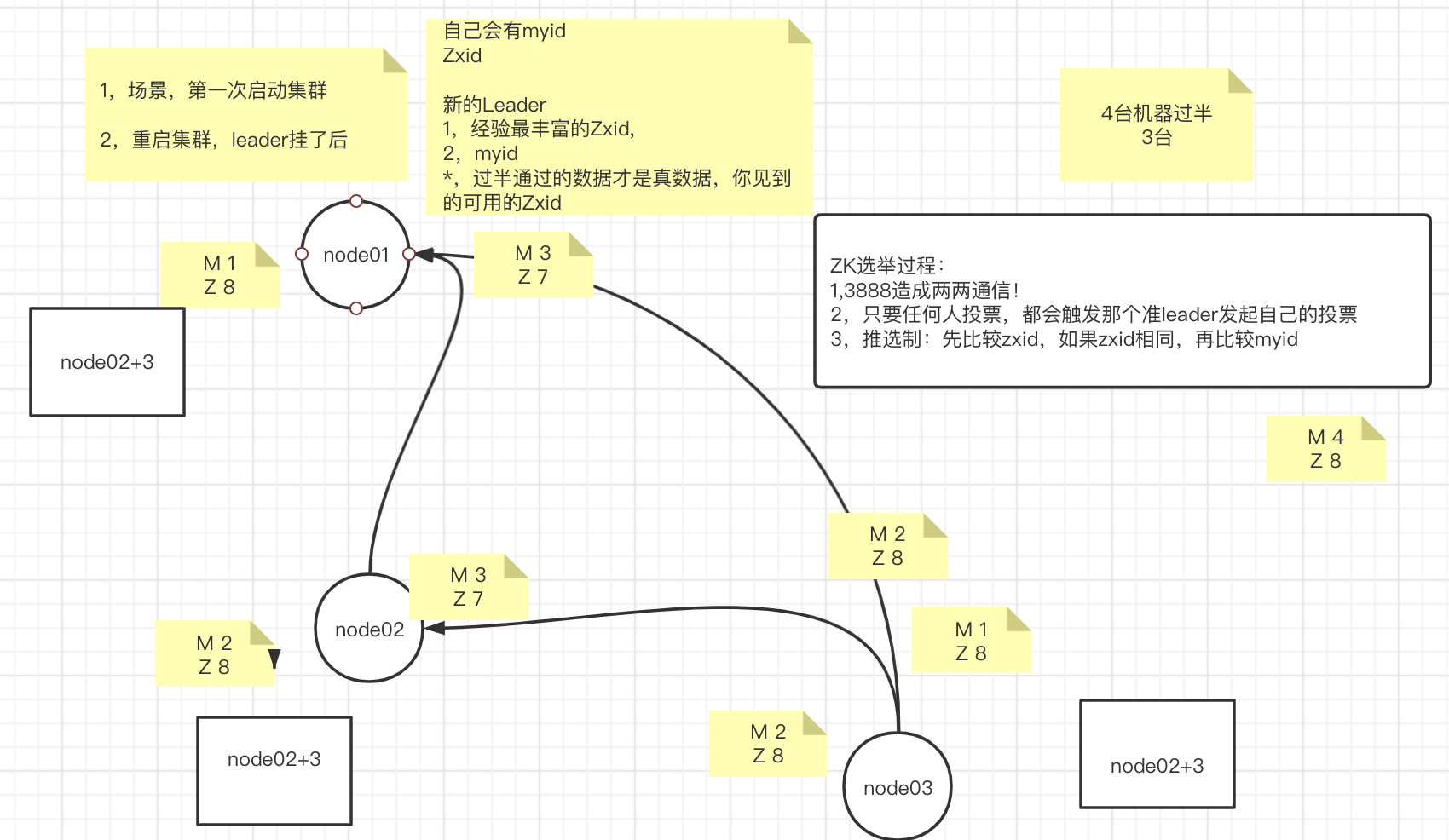
上面场景中如果node03先发现Leader不可用了时如何进行投票的
- node03先投自己一票,记录在内存中,然后将自己的Zxid和myid信息通过socket连接(3888)发送给node01、node02
- node01和node02收到投票和信息之后跟自己的信息做对比,返回一个投票结果。并且会被动触发步骤1中的给自己投票,并且发送自己的Zxid和myid信息给其他节点
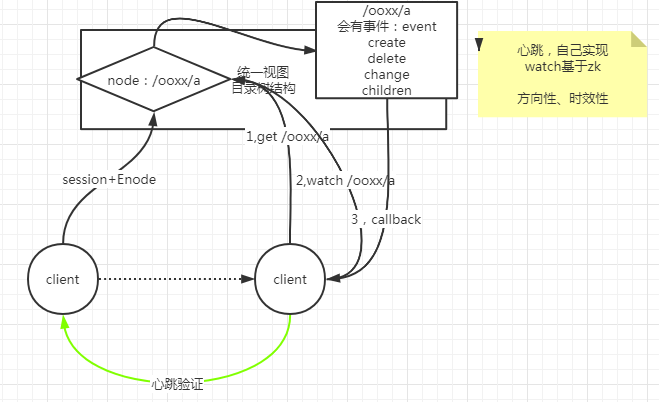
# Watch
# API
# Hello World
package xyz.yowei;
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.util.concurrent.CountDownLatch;
public class App
{
public static void main( String[] args ) throws Exception {
CountDownLatch countDownLatch = new CountDownLatch(1);
//zk是有session概念的,没有连接池的概念
//watch:观察,回调
//watch的注册值发生在 读类型调用,get,exites。。。
//第一类:new zk 时候,传入的watch,这个watch,session级别的,跟path 、node没有关系。
ZooKeeper zooKeeper = new ZooKeeper("192.168.137.101:2181,192.168.137.102:2181,192.168.137.103:2181,192.168.137.104:2181", 3000, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
Event.KeeperState state = watchedEvent.getState();
Event.EventType type = watchedEvent.getType();
System.out.println("default watch: event="+ watchedEvent.toString());
switch (state) {
case Unknown:
System.out.println("default watch: unknown");
break;
case Disconnected:
System.out.println("default watch: Disconnected");
break;
case NoSyncConnected:
System.out.println("default watch: NoSyncConnected");
break;
case SyncConnected:
System.out.println("default watch: SyncConnected");
countDownLatch.countDown();
break;
case AuthFailed:
System.out.println("default watch: AuthFailed");
break;
case ConnectedReadOnly:
System.out.println("default watch: ConnectedReadOnly");
break;
case SaslAuthenticated:
System.out.println("default watch: SaslAuthenticated");
break;
case Expired:
System.out.println("default watch: Expired");
break;
}
switch (type) {
case None:
System.out.println("default watch: type=None");
break;
case NodeCreated:
System.out.println("default watch: type=NodeCreated");
break;
case NodeDeleted:
System.out.println("default watch: type=NodeDeleted");
break;
case NodeDataChanged:
System.out.println("default watch: type=NodeDataChanged");
break;
case NodeChildrenChanged:
System.out.println("default watch: type=NodeChildrenChanged");
break;
}
}
});
countDownLatch.await();
ZooKeeper.States state = zooKeeper.getState();
switch (state) {
case CONNECTING:
System.out.println("zookeeper state: CONNECTING");
break;
case ASSOCIATING:
System.out.println("zookeeper state: ASSOCIATING");
break;
case CONNECTED:
System.out.println("zookeeper state: CONNECTED");
break;
case CONNECTEDREADONLY:
System.out.println("zookeeper state: CONNECTEDREADONLY");
break;
case CLOSED:
System.out.println("zookeeper state: CLOSED");
break;
case AUTH_FAILED:
System.out.println("zookeeper state: AUTH_FAILED");
break;
case NOT_CONNECTED:
System.out.println("zookeeper state: NOT_CONNECTED");
break;
}
/*
增
*/
String path = zooKeeper.create("/xxoo", "test".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
System.out.println("created node return "+path);
zooKeeper.create("/ooxx","123".getBytes(),ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL, (rc, path1, o, s1) -> {
System.out.println("rc="+rc +"&path="+ path1 +"&object="+o.toString()+"&s1="+s1);
},"");
/*
查
*/
Stat stat = new Stat();
// boolean watch 是否使用默认的watch,上面创建zookeeper时定义的watch
byte[] data = zooKeeper.getData("/xxoo", false, stat);
System.out.println("getData="+new String(data)+"&stat="+stat.toString());
zooKeeper.getData("/xxoo", new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
System.out.println("getData watch event="+watchedEvent.toString());
}
},stat);
/*
改
*/
//会触发上面的watch
Stat stat1 = zooKeeper.setData("/xxoo", "xxxx".getBytes(), 0);
//不会再触发上面的watch
Stat stat2 = zooKeeper.setData("/xxoo", "xxxxx".getBytes(), stat1.getVersion());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
- new Zookeeper的时候定义的watch是session级别的,如果连接的服务器断掉,客户端会收到callback,然后重新连接一个server,并且sessionid不变
# 分布式协调
# 扩展性
角色
- Leader
- Follower
- Observer
- 放大查询能力
读写分离
只有Follower才能参与选举,Observer不会参与选举
角色配置
server.1=node01:2888:3888 server.2=node02:2888:3888 server.3=node03:2888:3888 server.4=node04:2888:3888:observer1
2
3
4
# 可靠性
攘其外必先安其内
快速恢复Leader
一致性
最终一致性
过程中,节点是否对外提供服务
没有组建过半数的节点会shutdown自己的服务
# 案例
# 分布式配置
# 分布式锁
实现要点
争抢锁,只有一个客户端获得锁
没有完成就挂了会导致死锁,如何解决
临时节点,session
获得锁的人成功了,释放锁
锁释放了别人怎么知道
主动轮询、心跳
- 弊端:延迟、压力
watch
- 弊端:zookeeper会回调所有其他等待的客户端
序列节点+watch
- watch前一个,最小的获取锁,一旦最小的释放锁,zk只给第二个发事件回调